Abstract
Large Language Models (LLMs) suffer inference-time memory bottlenecks dominated by the attention Key-Value (KV) cache, which scales with model size and context length. While KV-cache quantization alleviates this cost, bit allocation between keys and values is often tuned heuristically, lacking theoretical grounding and generalizability. This paper proposes two theorems that anchor mixed-precision KV quantization in the intrinsic geometry of Transformer models. First, key projections systematically have larger spectral and Frobenius norms than value matrices, implying higher information density along the key path. Second, for any given memory budget, prioritizing precision for keys over values strictly reduces quantization error and better preserves accuracy. Empirical evaluations across various prominent LLMs and benchmarks show that key-favored allocations (e.g., 4-bit keys, 2-bit values) retain up to 98.3% accuracy compared to uniform allocations (e.g., 4-bit for both), while conserving memory. These results transform bit allocation from ad hoc tuning into a theoretically grounded, geometry-driven design principle for efficient LLM inference. Source code is available at https://github.com/mohsenhariri/spectral-kv.
Introduction
Large Language Models (LLMs) have rapidly scaled in recent years, driving major advances in generative capabilities and reasoning performance [1, 2]. Model size has increased by several orders of magnitude: GPT has grown from 117M parameters in GPT-1 [3] to 1.5B in GPT-2 [4], 175B in GPT-3 [5], and 1.8T in GPT-4 [6]. Open-source models have followed a similar trajectory, with Llama reaching 2T parameters [7], Mistral Large scaling to 123B [8], and DeepSeek V3 to 671B [9].
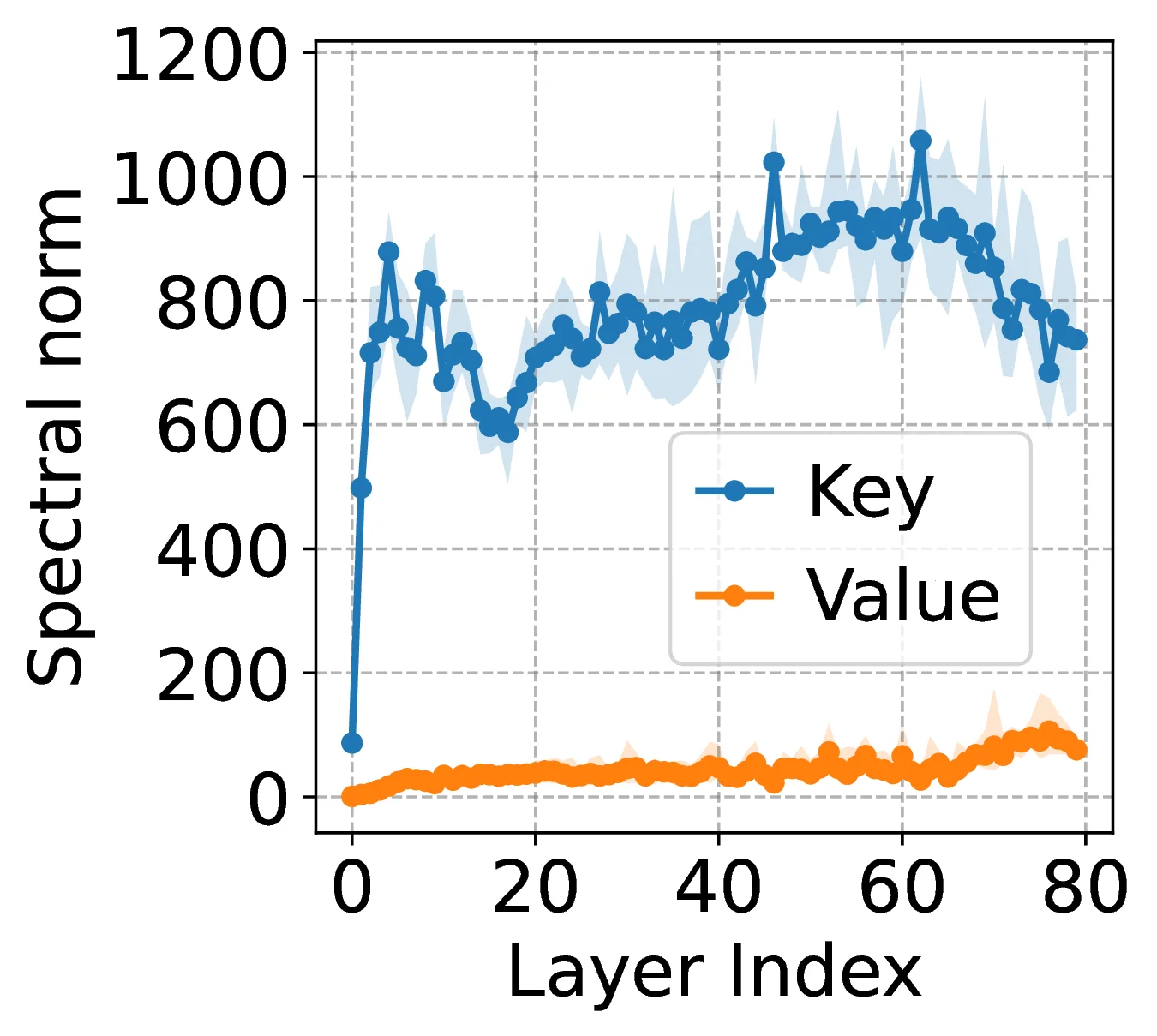
However, this rapid growth has introduced severe inference-time memory bottlenecks, primarily due to the Key-Value (KV) cache [10]. As parameter counts increase, context lengths must also grow to support more complex reasoning, which further expands the KV cache and strains GPU memory [11]. Modern systems already support extremely long contexts [12, 13, 14, 15], reaching up to 10 million tokens [16], making memory-efficient methods essential.
KV cache quantization refers to reducing the precision of KV tensors (e.g., BF16 to INT4), which can provide substantial memory savings while maintaining controlled accuracy degradation, provided applied strategically [17, 18]. Although many KV quantization methods have been proposed, most determine key–value bit splits through ad hoc hyperparameter tuning on cache statistics (e.g., inference-time activations) rather than grounding them in intrinsic model properties (e.g., model weights). This raises a fundamental question: How should bits be allocated in a principled and generalizable way?
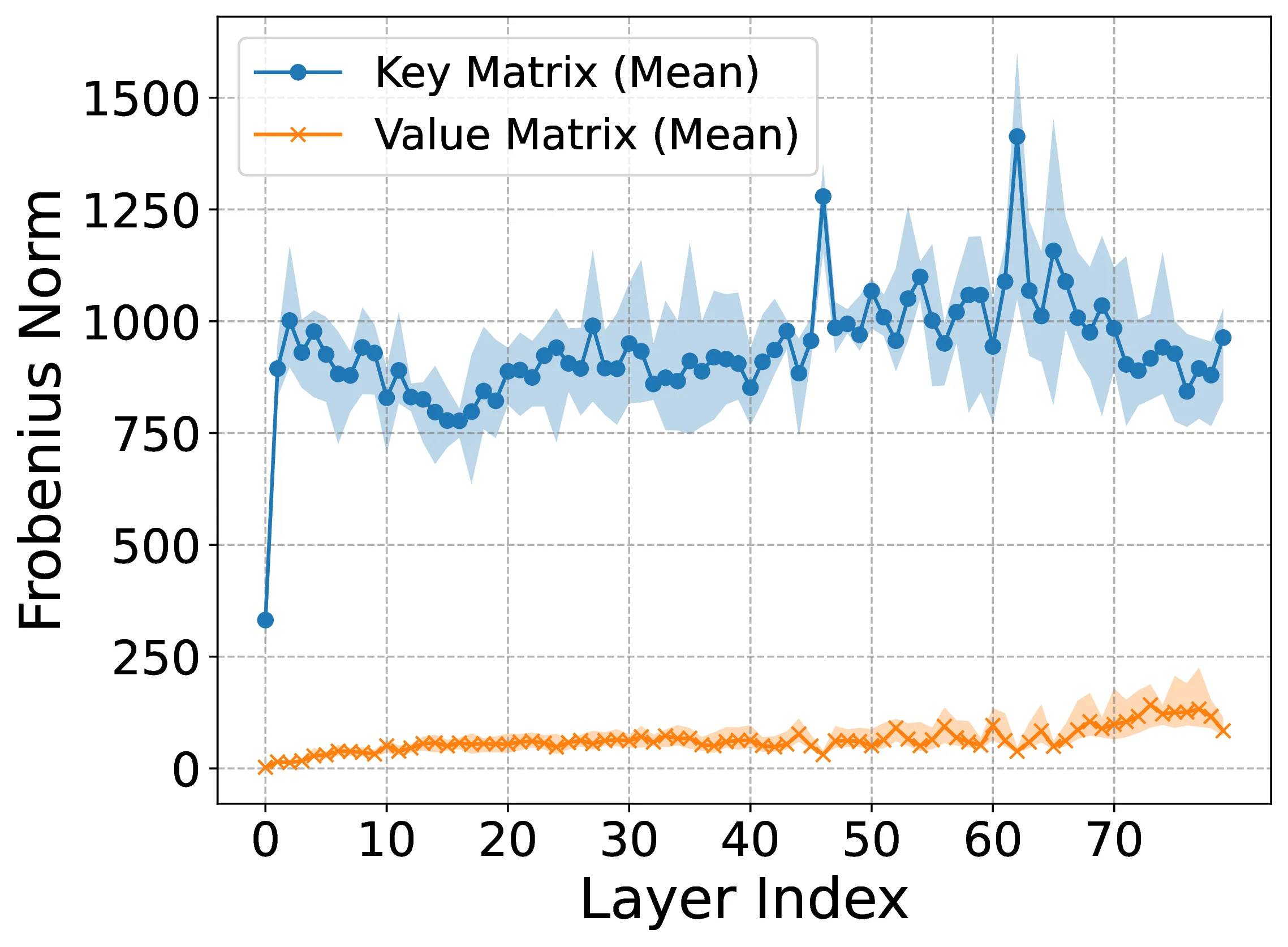
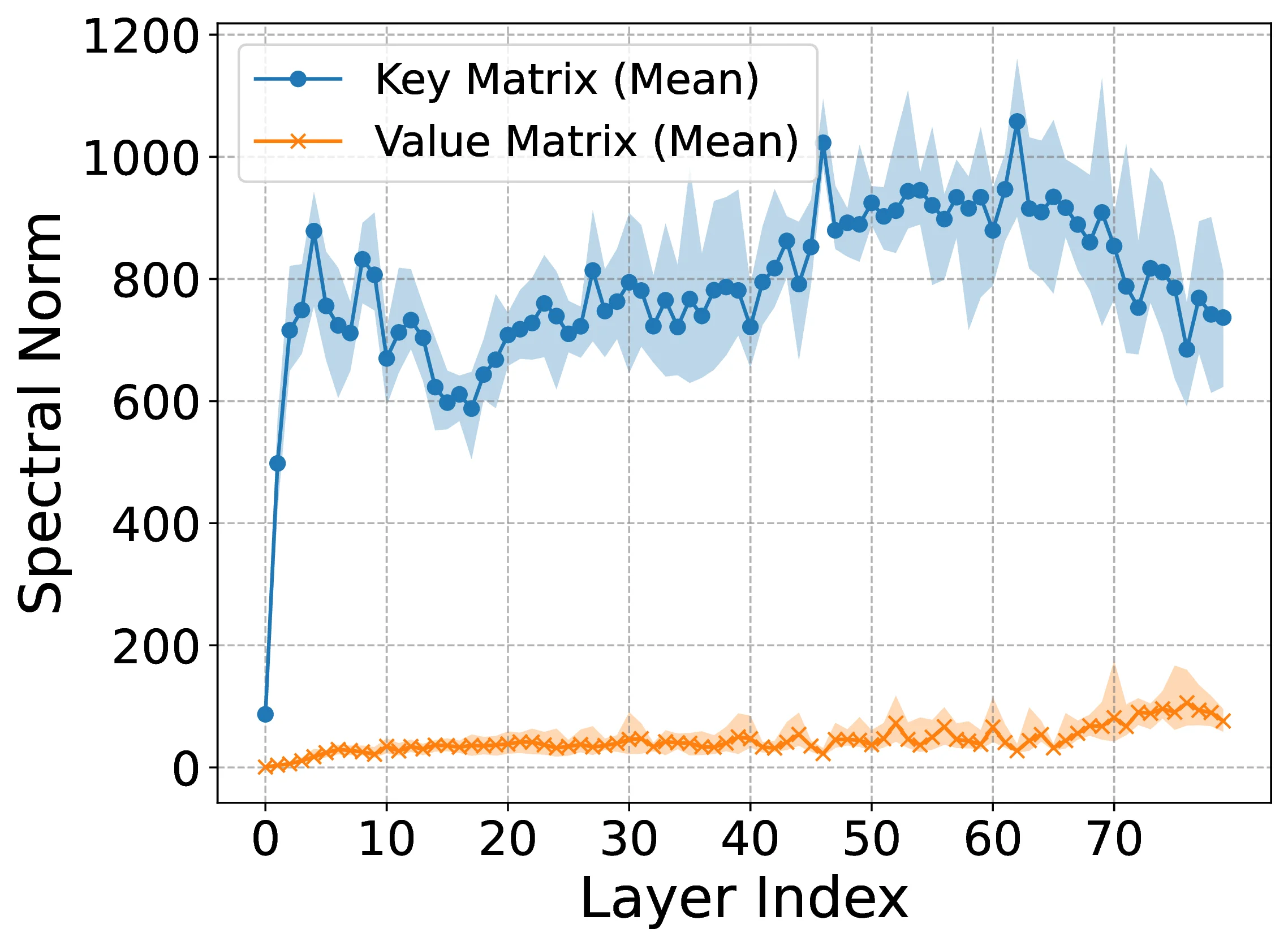
To answer, Figure 1 illustrates two key observations. First, key caches () consistently have larger spectral norms than value caches (). Second, assigning more bits to keys (e.g., ) improves accuracy across multiple models compared to key-underprovisioned allocations (). These motivate a deeper investigation into the distinct roles of key-value weights (i.e., and ) in attention mechanisms and their implications for quantization performance. Toward this, our contributions are:
- We propose the theorem, proving that the expected spectral and Frobenius norms of predominantly exceed those of across prominent LLM models (i.e., Llama3 and Mistral herds). We then derive the theorem, establishing the theoretical foundation on why assigning higher precision to than strictly reduces quantization error, enabling greater KV-cache compression while maintaining accuracy.
- We corroborate and operationalize these theorems across a diverse set of models (Llama-3.2-1B/3B/8B, Llama-3.3-70B, Phi-4-14B, Qwen3-0.6B/1.7B/4B/8B, DeepSeek-R1, Mistral-0.3-7B), datasets (C4, MMLU, GSM8K, EQ-Bench, CoQA, and LongBench), and two quantization backends (Optimum Quanto and HQQ). Notably, retains 98.3% (1-shot) and 94.1% (5-shot) accuracy of accuracy while reducing KV-cache memory by 25%, demonstrating both the theoretical soundness and practical effectiveness of the proposed strategy.
- Owing to its efficient one-off tunability, we show that our geometry-driven mixed-precision strategy is orthogonal to existing inference-time KV quantization methods and can be seamlessly integrated to yield synergistic gains. In a case study with rotation-based outlier redistribution, combining a key-prioritized quantization () with key-only rotation outperforms by 4.4-18% in accuracy across tasks. In contrast, rotating value caches is unnecessary and sometimes detrimental
Background and Related Work
KV Quantization.
Quantization methods for LLMs can be categorized by timing: training-time and post-training (PTQ) [19]. Training-time quantization integrates quantization into model training, typically achieving higher accuracy by quantizing weights or activations during the optimization process. However, it requires labeled data and incurs significant training overhead. PTQ applies quantization after training, avoiding retraining costs and labeled data requirements [18], but sometimes yields lower accuracy.
PTQ can target different model components: weights, activations, or the KV cache. Weight-only quantization [20, 21, 22] achieves strong accuracy but does not reduce activation or KV memory. Weight-activation quantization [23, 24, 25] reduces overall memory but often sacrifices accuracy. KV quantization offers the best of both: it targets the rapidly growing KV cache [26], providing activation-level memory savings while maintaining the accuracy of weight-only methods [27].
Existing KV Quantization Schemes.
KV quantization methods can be categorized by how they treat keys and values [28]:
- Outlier redistribution. These methods smooth or relocate outliers (i.e., unusually large activation values that dominate quantization ranges) in KV tensors, e.g., SmoothQuant [24], AWQ [22], and OmniQuant [25].
- Fixed-precision. A single bit-width is used for both keys and values, ignoring their different roles and statistical properties [29, 30, 31].
- Mixed-precision. Different bit-widths are assigned to different parts of the cache [32, 27, 33, 34, 35, 36, 37].
While mixed-precision schemes are the most flexible, existing methods have not systematically explored asymmetric bit allocation between keys and values. KVQuant [32], for example, focuses on vector-wise outlier handling rather than analyzing keys and values separately. Only a few methods have attempted to address this issue, and even then, only superficial insights have been gained.
Needs and Gaps.
Despite rapid progress in KV quantization, several needs from the LLM research community remain unmet. First, there is a need for principled strategies to guide bit allocation. Current frameworks either treat the key-value split as a hyperparameter tuned through grid search [37]
or rely on heuristics derived from cache statistics (e.g., activation ranges or distributions collected at inference time) [38, 39, 40]. These approaches are costly, model- or data-specific, and provide little theoretical insight into the inherent differences between keys and values. Second, there is a need to understand and exploit key-value asymmetry. Existing works such as KVTuner [37], SKVQ [35], and QAQ [34] briefly observe that allocating more bits to keys can preserve accuracy, but none explain why or propose a generalizable strategy. KVTuner reports differences in attention vs. perplexity errors across bit pairs without analysis; SKVQ finds asymmetric allocations (e.g., 2-bit keys, 1.5-bit values) through hyperparameter search rather than model structure; and QAQ focuses on different data types for keys and values rather than bit-width asymmetry. Third, there is a need for lightweight, modular methods that integrate seamlessly with existing KV quantization frameworks. The studies mentioned above often involve complex, runtime-dependent procedures that are difficult to generalize or combine, limiting their drop-in applicability and composability with other techniques.
Our Perspective.
We address these needs by deriving bit allocation strategies directly from model weights, analyzing spectral and Frobenius norms of key and value matrices. Our approach is lightweight, incurring only a one-off analytical cost per model without any inference-time introspection; generalizable, since weight statistics are invariant across inputs and tasks; and principled, grounding allocation in linear algebraic properties rather than heuristic search. Moreover, our mix-precision quantization oracle is orthogonal to existing KV quantization techniques, paving a foundation that others can build upon. For example, pairing our mixed-precision allocation with rotation-based outlier redistribution techniques yields complementary improvements in both accuracy and memory savings. In this way, we elevate bit allocation from an ad hoc design choice to a geometry-informed building block for future KV quantization frameworks.
Norm Dynamics of KV Weights
We now establish a theoretical foundation for mixed-precision KV-cache quantization by analyzing the intrinsic geometry of the key and value projection weights. Our analysis proceeds in two steps. First, we prove that key weights systematically exhibit larger spectral and Frobenius norms than value weights (), a property that is preserved in the resulting key and value caches. Second, we demonstrate that this norm gap directly impacts quantization error, providing a formal guarantee that assigning higher bit precision to keys yields strictly lower distortion and higher inference accuracy than symmetric or inverted allocations ().
: Key Weights Dominate in Norm
The key weight matrix maps hidden states into the key cache, whereas the value weight matrix determines the representations retrieved during attention. Because quantization error scales approximately with the dynamic range of the signal, the relative magnitudes of and , e.g., their Frobenius or spectral norms, indicate which cache is more sensitive to quantization.
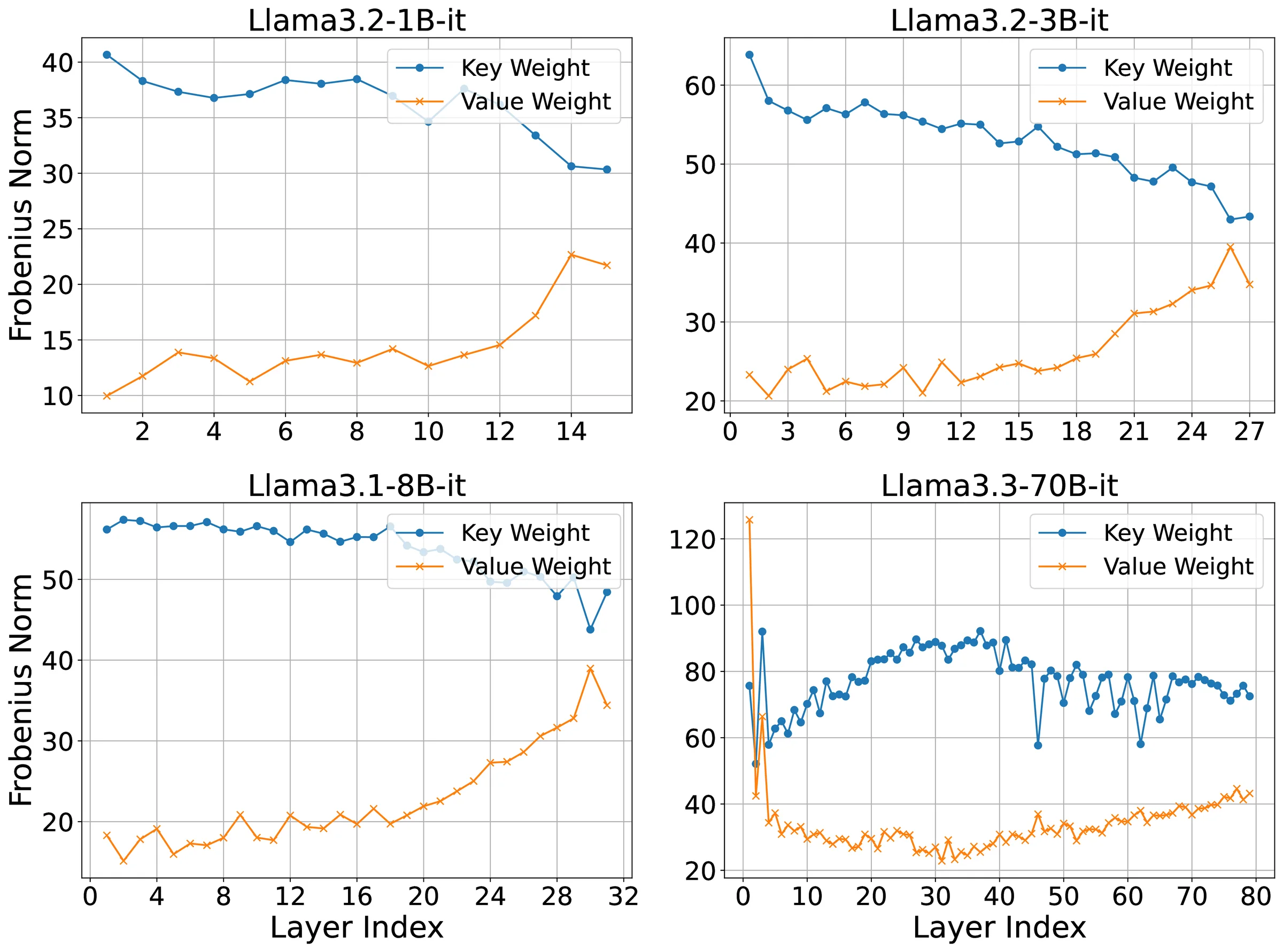
Empirical measurements across four Llama-3 herds (Figure 2) show that the Frobenius norm of consistently exceeds that of in nearly every layer; the same ordering holds for spectral norms. This persistent gap motivates the following theorem.
theorembox[]
Let and denote the key and value projection matrices in a Transformer. Then
theorembox
The detailed proof is provided in Appendix 11.2. The core idea here is to examine how the Frobenius norms of the key and value weight matrices evolve during training. The analysis begins with Xavier initialization [41], where all projection matrices have identical expected norms, and tracks their evolution under stochastic gradient descent (SGD). Intuitively, play a dual role: they shape the attention map and determine what representations are stored in the cache. Each input is multiplied by to produce keys that interact multiplicatively with the queries derived from (i.e., the query projection). As training proceeds, typically grows to sharpen attention, amplifying the gradient signals backpropagated into . By contrast, only influences post-attention representations, so its gradients lack this multiplicative amplification. This architectural asymmetry causes to receive systematically larger updates, leading to persistently larger norms over time.
This phenomenon is ubiquitous. Appendix 13.2 offers analogous results for Mistral family [8], demonstrating the generality of the pattern. We next show that this norm disparity has direct consequences for quantization.
: Key-Favored Allocation Minimizes Quantization Error
Theorem ? implies that, on average, and their resulting activations, , have larger magnitude than their value counterparts. Since quantization error under uniform scalar quantization scales with the signal energy, assigning equal bit precision to both is sub-optimal.
Consider an additive-residual Transformer block (layer normalization omitted for clarity [42]):
Quantizing to introduces an error bounded by
After layers, the worst-case deviation accumulates multiplicatively:
Because the expected norms satisfy
any quantization noise injected along the key path is amplified more strongly through the network.
Let be the hidden-state matrix at a given layer. The same input generates both caches via
Multiplying the previous inequality by and applying sub-multiplicativity of the Frobenius norm yields
i.e., the norm gap persists in the caches.
Quantization Error and Norm Magnitude.
For a matrix , the squared Frobenius norm equals the total signal energy and the sum of squared singular values. When quantized with -bit uniform scalar quantization, the expected mean-square error satisfies
with constants depending only on the quantizer. Since key and value caches have identical shape, minimizing quantization error reduces to allocating bits in proportion to their energy. When and equal bit-widths are used, key-cache error dominates:
This asymmetry in quantization error directly motivates an asymmetric bit allocation strategy, formalized as the following theorem:
theorembox[]
Let denote the bit allocations for key and value caches under a uniform scalar quantizer. For any pair with , the expected inference accuracy is strictly higher than for the swapped allocation , provided that . theorembox
Figure ? provides empirical evidence for this effect. For Llama 3.3-70B on C4, the singular value spectra of the key caches consistently exceed those of the value caches beyond the top singular mode, indicating higher representational significance throughout the spectrum. Appendix 13.3 extends this analysis to the full singular value range, where Figure ? shows layer-wise Frobenius and spectral norms, all consistently revealing larger magnitudes for keys than for values.
The theoretical underpinnings of this phenomenon are established in Theorems ? of Appendix 12.2 and ? of Appendix 12.3, which derive a norm-dependent upper bound on the quantization error of an arbitrary matrix M. Appendix 12.4 then applies this bound to the key and value caches, showing that the larger norms of the key caches translate into proportionally higher quantization errors under equal bit allocations.
figure*[htbp]
Figures/Llama3.3-70B-it_5_to_end_L.pdf Singular value spectra of key and value activations in Llama 3.3-70B on C4 benchmark dataset. The x-axis shows singular value indices, ordered from the 5th largest onward for cleaner illustration, and the y-axis shows their magnitudes. Shaded regions mark the minimum-maximum range across attention heads within each layer, while dashed lines indicate the mean at each index. Beyond the top singular value (i.e., the spectral norm), key activations consistently exhibit larger singular values than value activations across the spectrum, highlighting their greater representational capacity. Full spectra are provided in Figure ? of Appendix 13.3.
figure*
Results
Experimental Setup
Three evaluations are conducted: (i) a quantization-error analysis, which measures reconstruction error across different bit-widths; (ii) a downstream task accuracy evaluation, which assesses how mixed-precision KV cache quantization affects model accuracy on practical benchmarks; and (iii) an integration case study with rotation-based outlier distribution methods, which investigates the effect of combining mixed precisions with rotation strategies. Full details on compute resources and software configurations are supplied in Appendix 14.
Texts/table_quant_error
Quantization-Error Evaluation. PyTorch’s weight-packing quantization is applied without residual buffers or activation grouping to isolate quantization effects. Ten random sequences are sampled from C4 [43], MMLU [44], and GSM8K [45], padded to the longest length, and generated autoregressively for up to 1,000 tokens. Both per-layer and per-head reconstruction errors are computed, along with global averages across all heads, layers, and tokens, to offer a comprehensive view of bit-width sensitivity. This experiment spans seven models, including Llama-3.2-1B, Llama-3.1-8B [46], Phi-4-14B [47], Mistral-0.3-7B [8], Qwen-2.5-14B, Llama-3.3-70B, DeepSeek-R1-Qwen-14B, Phi-3-Medium-128K [48], and Llama-3.1-Nemotron-70B [49].
Downstream Task Accuracy. Two representative quantization backends are employed. Optimum Quanto applies token-wise (per-row) quantization with mixed 2/4-bit precision on Llama-3.2-1B, Llama-3.1-8B, Phi-4-14B, and DeepSeek-R1-Qwen-14B. HQQ [50] applies channel-wise (per-column) quantization with bit-widths on Llama-3.1-8B, Llama-3.2-1B, Llama-3.2-3B, and Qwen3-0.6B/1.7B/4B/8B [51]. A 64-token residual buffer (which stores the most recent tokens in full precision before being periodically flushed) and 128-element activation grouping (which quantizes activations in fixed-size blocks to reduce overhead) are adopted to mirror practical decoding configurations used in KIVI [31], Flash-Decoding [52], and Marlin [53], ensuring that the evaluation reflects realistic deployment rather than idealized settings. Accuracy is measured on three generative benchmarks: GSM8K [45], CoQA [54], and EQ-Bench [55], which collectively probe mathematical reasoning, conversational QA, and structured long-form generation.
Integration with Rotation-Based Methods. QuaRot [56] is selected for this case study. It applies structured randomized Hadamard rotations to activations before quantization, effectively dispersing outliers and improving the uniformity of the quantization distribution. A three-dimensional design space is explored, spanning bit-width allocation, group size configuration, and rotation strategies. Specifically, mixed-precision settings , , , and ; key and value group sizes in ; and four rotation strategies (no rotation, key-only, value-only, and both). The evaluation encompasses generative tasks including CoQA, GSM8K, EQ-Bench, and LongBench, utilizing the same seven models as in quantization-error evaluation.
Mixed-Precision Quantization Error
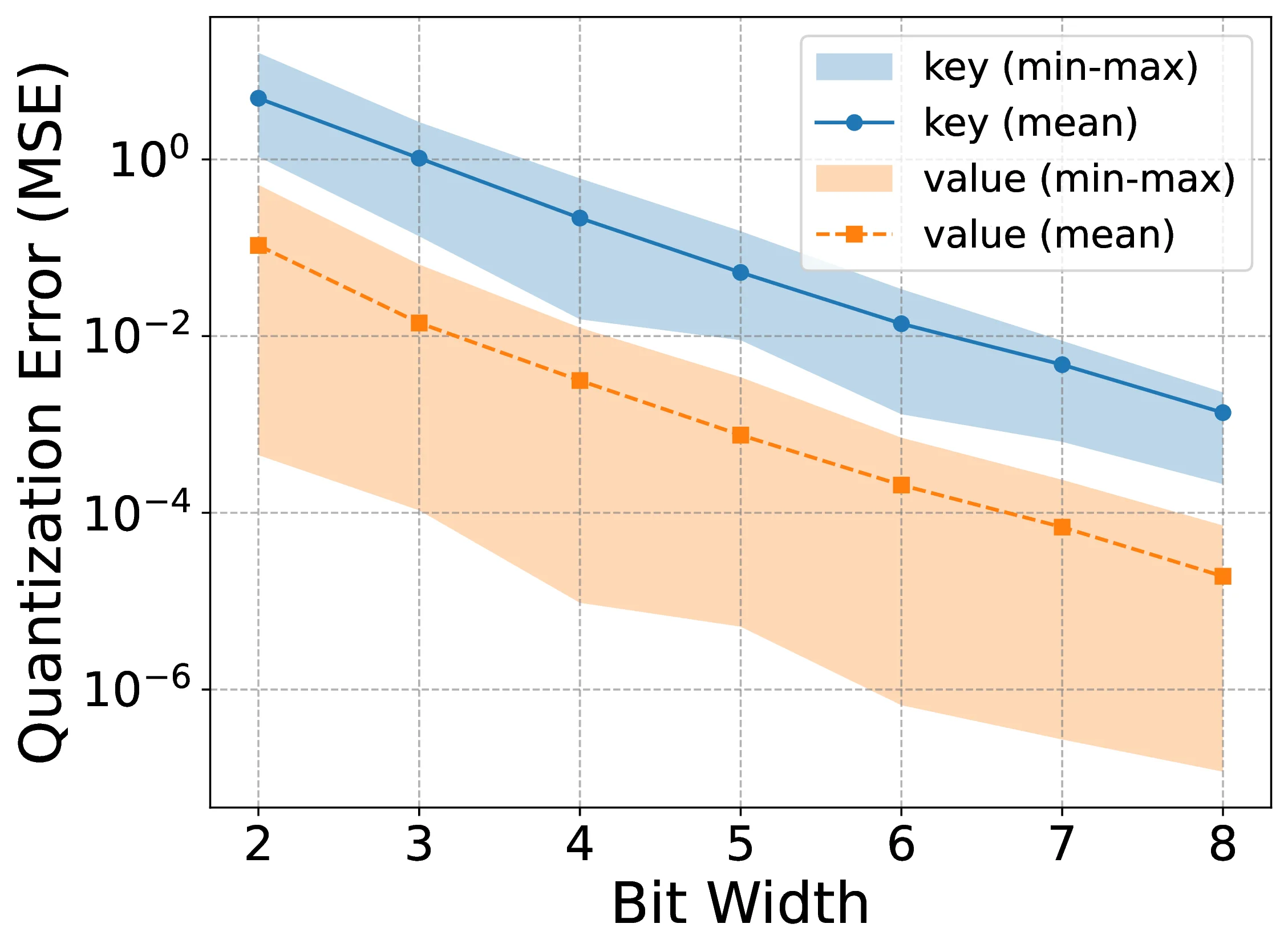
Table ? reports reconstruction errors at 2-, 3-, and 4-bit precision for seven representative models spanning multiple model families (Llama, Phi, Mistral, Qwen, DeepSeek) and datasets; full results appear in Appendix 13.4. Figure 6 shows the complete error curves for Llama-3.3-70B on C4, and Figure ? provides a per-layer breakdown for Llama-3.1-8B. Across all models, datasets, and bit-widths, key caches consistently incur larger reconstruction errors than value caches, and this gap remains stable across precision levels. These findings empirically support the theoretical prediction that key representations have higher energy and are therefore more sensitive to quantization.
Mixed-Precision Downstream Accuracy
Table ? summarizes the Optimum Quanto results on GSM8K under both 1-shot and 8-shot Chain-of-Thought (CoT) prompting. Although CoT prompting can sometimes reduce reasoning accuracy, it is included here to assess the impact of longer contexts on quantized decoding. Across four representative models, including Llama-3.2-1B, Llama-3.1-8B, Phi-4-14B, and DeepSeek-R1-Qwen-14B, a consistent pattern emerges: allocating higher precision to the key cache () preserves accuracy substantially better than the inverse (). On average, recovers approximately 94% of the full-precision baseline, whereas value-favored allocations incur losses of up to 30 percentage points (pp). The performance gap widens with model scale; for instance, under 1-shot GSM8K, the configuration outperforms by 30pp on Llama-3.2-1B and by 16pp on Phi-4-14B. Notably, nearly matches the symmetric baseline despite halving the value bit budget, indicating that downstream performance is primarily constrained by key precision.
Texts/table_quanto
Texts/table_hqq
The HQQ results, shown in Table ?, extend these observations to a broader range of bit-widths, model scales, and tasks. The analysis systematically compares against for , where denotes the mean accuracy over all bit-widths of the other cache. This directly addresses the question: "If bits are available, should they be allocated to keys or values?" Across all models (0.6B-32B) and datasets (GSM8K, CoQA, EQ-Parseable), the answer is consistently "keys". At ultra-low precision (1-2 bits), the advantage is especially pronounced; for instance, on GSM8K, allocating a single extra bit to keys with 1-bit quantization yields gains of +48pp for Qwen3-8B. Similar trends hold on EQ-Bench and CoQA: for Qwen3-0.6B on EQ-Parseable, prioritizing keys delivers up to +62pp, and key-first allocations never underperform value-first ones in any configuration. Even at moderate precisions (4-6 bits), key-centric allocation continues to offer 7-12pp improvements for 8-14B models, indicating that the advantage persists well beyond extreme compression.
On average, retains 98.3% accuracy of (CoQA: 99.2%, EQ-Bench: 99.35%, GSM8K: 97.7%; worst: 88.3%, best: 103.5%).
More detailed downstream accuracy results are provided in Appendix 13.5. Overall, downstream accuracy is far more sensitive to key precision than to value precision. Across both token-wise and channel-wise quantization schemes, model scales, and task types, assigning the higher bit-width to consistently yields near-baseline accuracy while substantially reducing KV memory. This establishes a simple, backend-agnostic design principle for mixed-precision KV cache quantization: More for keys, less for values.
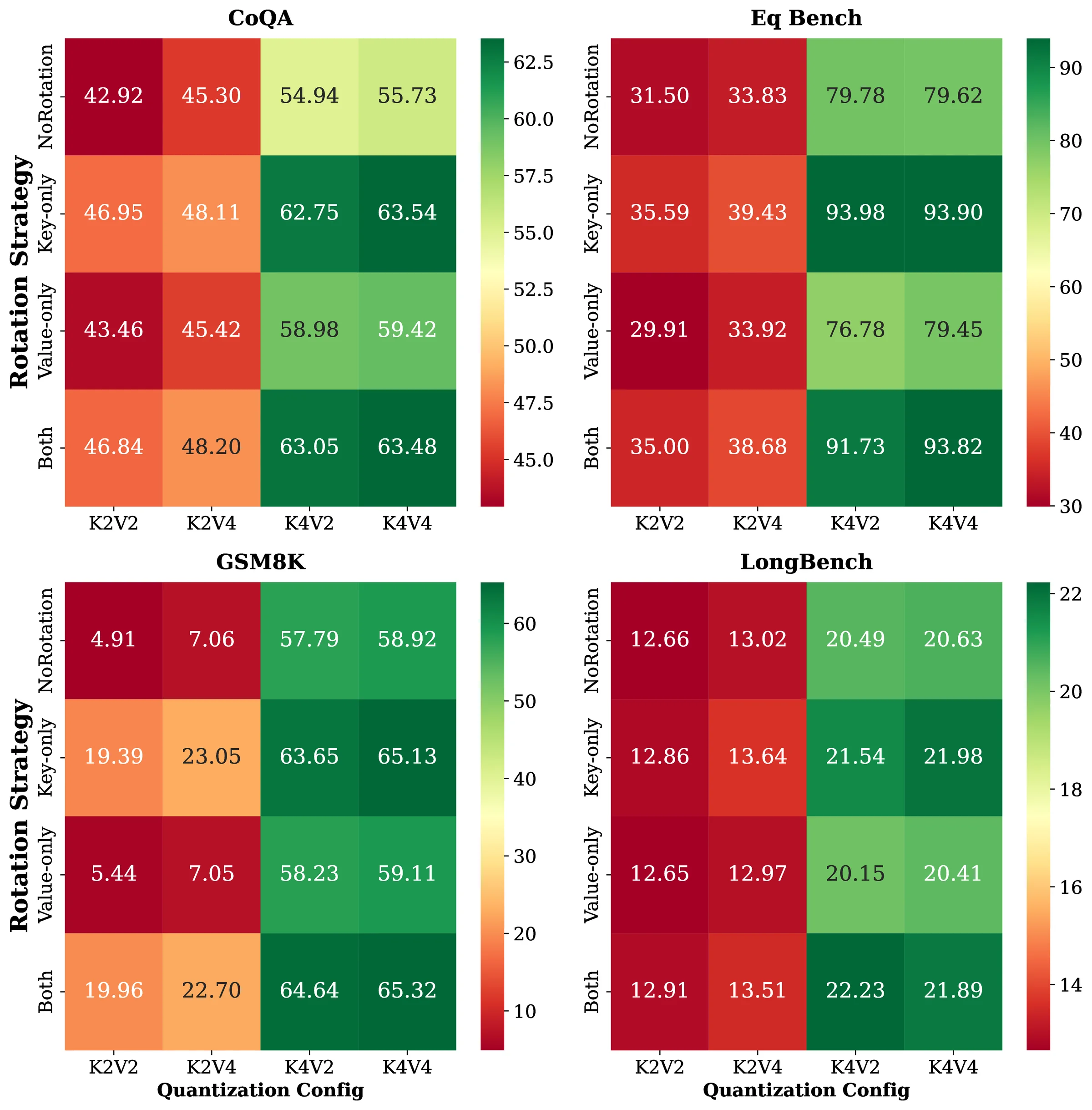
Integrating with Rotation-Based Methods
Figure 3 visualizes how rotation interacts with key-value bit allocations. Across all tasks, applying rotation to keys consistently yields larger gains than applying it to values. Notably, applying key-only rotation to the configuration achieves accuracy that closely matches the full baseline, indicating that the primary benefits of rotation arise from mitigating key outliers. These trends are consistent across tasks and model scales, reinforcing that rotation is most effective when applied in conjunction with key-favored bit allocation.
Appendix 13.6 presents detailed downstream results illustrating the synergistic effects of integrating rotation with mixed-precision quantization across tasks and models. It also examines the impact of key and value group sizes, showing that smaller sizes are beneficial for due to higher information density, whereas larger group sizes suffice for given lower sensitivity to quantization.
Conclusion
As large language models increasingly devote most of their inference cost to KV-cache storage and access, effective cache compression has become essential for practical deployment. This work provides a theoretically grounded justification and solution to the bit-allocation problem by bridging model geometry and quantization design. We theoretically establish that key projections consistently carry higher information density than value projections. Building on this, we show that allocating higher precision to keys and lower precision to values minimizes quantization error. Extensive experiments across nine model families, six benchmarks, and two hardware-aligned backends validate this principle: a precision split reliably recovers up to of accuracy while significantly reducing memory consumption. Moreover, we demonstrate that our geometry-driven strategy is orthogonal to rotation-based outlier redistribution methods, enabling seamless integration and further accuracy gains. These findings elevate bit allocation from empirical tuning to a theoretically grounded geometry-driven design principle, providing clear guidance for efficient deployment and future hardware-algorithm co-design.
Limitations
While our geometry-driven mixed-precision quantization framework demonstrates both theoretical soundness and practical effectiveness through rigorous analysis and extensive experiments, several limitations remain. First, all evaluations are conducted with a maximum context length of 2,000 tokens, which reflects common inference-time configurations but does not fully capture the behavior of models operating at much larger context windows. Extending the approach to longer contexts may expose additional challenges, including increased quantization sensitivity and higher memory management overheads. Addressing these factors is an important direction for future work.
Ethical Considerations
This research aims to reduce the memory and computational costs of large language model inference by utilizing efficient KV-cache quantization. Such improvements have the potential to lower energy consumption and broaden access to language models in resource-constrained settings, promoting more sustainable and inclusive deployment. However, any compression technique entails accuracy trade-offs, which must be carefully monitored to avoid disproportionate impacts in high-stakes domains such as healthcare, law, or finance. Responsible deployment requires thorough evaluation of model behavior under mixed-precision settings, particularly for safety-critical applications.
Acknowledgment
This research was supported in part by NSF awards 2117439, 2112606, and 2320952.
Appendix
Appendix
Dynamics of the Norms of Key and Value Weight Matrices
Preliminaries and Notation
Training Dynamics of Frobenius Norms
We compare the long-time behavior of the Frobenius norms of the key () and value () weight matrices of a single-head self-attention layer trained with stochastic gradient descent (SGD). We show that, under standard isotropic assumptions, grows faster than .
Update rule. At step , the weights follow
with learning rate . Squaring the Frobenius norm of both sides gives
where
Expectation over mini-batches. Taking an expectation over mini-batches yields
In high-dimensional weight space, the gradient is almost orthogonal to the current weights, making the second term negligible. Hence,
Throughout, we assume Xavier initialization: each entry of and is drawn i.i.d. from a zero-mean distribution whose variance preserves the input scale [41].
The attention outputs are
where and . Differentials give
so that
Similarly, writing ,
yielding
Squaring the Frobenius norm of (8) and taking an expectation under the isotropic-input assumption,
where and .
For the key weights,
with the entry-wise variance of .
Substituting these expectations into (5) shows that
grows as , whereas grows as
Because itself increases during training, eventually dominates:
As shown in Equation 13, the expectation of the Frobenius norm of is greater than that of .
Quantization Error Bounds
We establish upper bounds on the quantization error incurred when a matrix is represented using a finite bit-width in two's complement format. Two theorems are presented: one that characterizes the error in terms of the spectral norm and another in terms of the Frobenius norm.
The first theorem demonstrates that the spectral norm of the quantization error is bounded by
This result implies that, for a given bit-width , matrices with larger spectral norms incur proportionally larger quantization errors. Consequently, a matrix that exhibits a larger spectral norm is more susceptible to quantization errors. To control error propagation in such matrices, a higher bit width is necessary.
The second theorem provides an analogous bound for the Frobenius norm,
Similar to the spectral norm result, this bound indicates that the quantization error, measured in the Frobenius norm, is directly proportional to the norm of the original matrix. Hence, matrices with larger Frobenius norms are also more vulnerable to quantization errors and would benefit from a higher precision during quantization.
Preliminaries
Let denote a real matrix whose entries are to be stored using a fixed number of bits in two's complement representation. The following notation is adopted:
- Bit Depth. Given bits in two's-complement format, each representable integer lies in the interval \[ q \-2^b-1, -2^b-1+1, , 2^b-1-1\. \]
- Maximum Entry Magnitude. Define \[ M = _1 i m, 1 j n |A_ij|. \]
- Scale Factor. Set \[ = M2^b-1-1. \] This choice ensures that the scaled entries lie within the representable range.
- Quantization. Define the integer matrix by equation* aligned Q_ij &= round(A_ij), \\ with Q_ij & \-2^b-1, , 2^b-1-1\. aligned equation*
- Dequantization (Reconstruction). The reconstructed matrix is given by \[ A_ij = Q_ij. \]
Objective. The aim is to bound the errors
in terms of , , , and the norms of .
Spectral Norm Error Bound
theorembox[Spectral Norm Error Bound for Uniform Quantization]
Let and be given. Consider two's complement quantization with a scale factor of
Define
Then, the following bound holds:
In approximate form for large ,
theorembox
proof Entrywise Bound. By construction,
Multiplying by gives
Thus,
Conversion to the Spectral Norm. Using the inequality
with , it follows that
Relating to . Since
the bound can be written as
For large , where , the bound becomes
proof
Frobenius Norm Error Bound
theorembox[Frobenius Norm Error Bound for Uniform Quantization]
Under the same setup as Theorem ?, the Frobenius norm of the quantization error satisfies
In approximate form,
theorembox
proof Entrywise Bound. As established,
Conversion to the Frobenius Norm. By definition,
which yields
Taking square roots leads to
Relating to . Since
it follows that and hence
For large , this simplifies to
proof
Remark. The results indicate that both the spectral norm and Frobenius norm errors satisfy similar approximate bounds:
Implications for KV Cache Quantization
Consider the key and value cache
with quantization bit-widths denoted by and , respectively. Let and denote the dequantized matrices, and define the quantization errors as
An empirical observation is that
where denotes either the spectral norm () or the Frobenius norm (). In practice, typically exhibits a larger norm than .
Spectral-Norm Perspective. Standard quantization error bounds yield
To achieve comparable spectral-norm errors (i.e., ), it is necessary that
Cancelling the common factor yields
or equivalently,
Since , it follows that .
Frobenius Norm (MSE) Perspective. The Frobenius norm of the quantization error corresponds directly to the mean-squared error (MSE) when normalized by the number of elements. Specifically, for a matrix with quantized approximation , the MSE is
where denotes the number of entries. Thus, controlling the Frobenius norm is equivalent to controlling the MSE up to a scaling factor.
The quantization error bounds under the Frobenius norm are given by
where is the sequence length and is the head dimension.
To ensure comparable Frobenius (or MSE) errors between keys and values, we require
which simplifies to
and therefore
Since typically , it follows that . This reinforces the earlier spectral-norm result: keys should be allocated more bits than values to achieve balanced quantization error under an MSE criterion.
Supplemental Results
Focus on Generative Tasks
We validate and operationalize our theorems across a diverse set of datasets, including C4, MMLU, GSM8K, EQ-Bench, CoQA, and LongBench. Our evaluation purposefully focuses on generative tasks, i.e., open-ended generation and free-form responses, because KV-cache quantization primarily affects the decoding phase rather than the prefill phase. To assess quantization error in isolation, we use C4 under a free-form decoding setup that mirrors pretraining usage, enabling us to analyze how compression directly distorts activations. To quantify downstream impact, we select GSM8K, CoQA, EQ-Bench, and LongBench, all of which rely on generate_until-style evaluation, where the model must produce extended, structured responses. In contrast, commonsense reasoning benchmarks (e.g., BoolQ, PIQA, HellaSwag, or DoRA) use log-likelihood scoring over candidate options and do not engage KV-cache quantization unless the input prompt itself is compressed. Consequently, such discriminative evaluations are orthogonal to our focus and were intentionally excluded.
Within LongBench, we surveyed all subtasks (gov_report, lcc, lsht, multi_news, narrativeqa, qasper, qmsum, repobench-p, samsum) and found that only gov_report and qmsum require substantial generation, with gov_report involving the longest outputs. Throughout this work, “LongBench” refers specifically to gov_report.
Key-Value Weight Norm
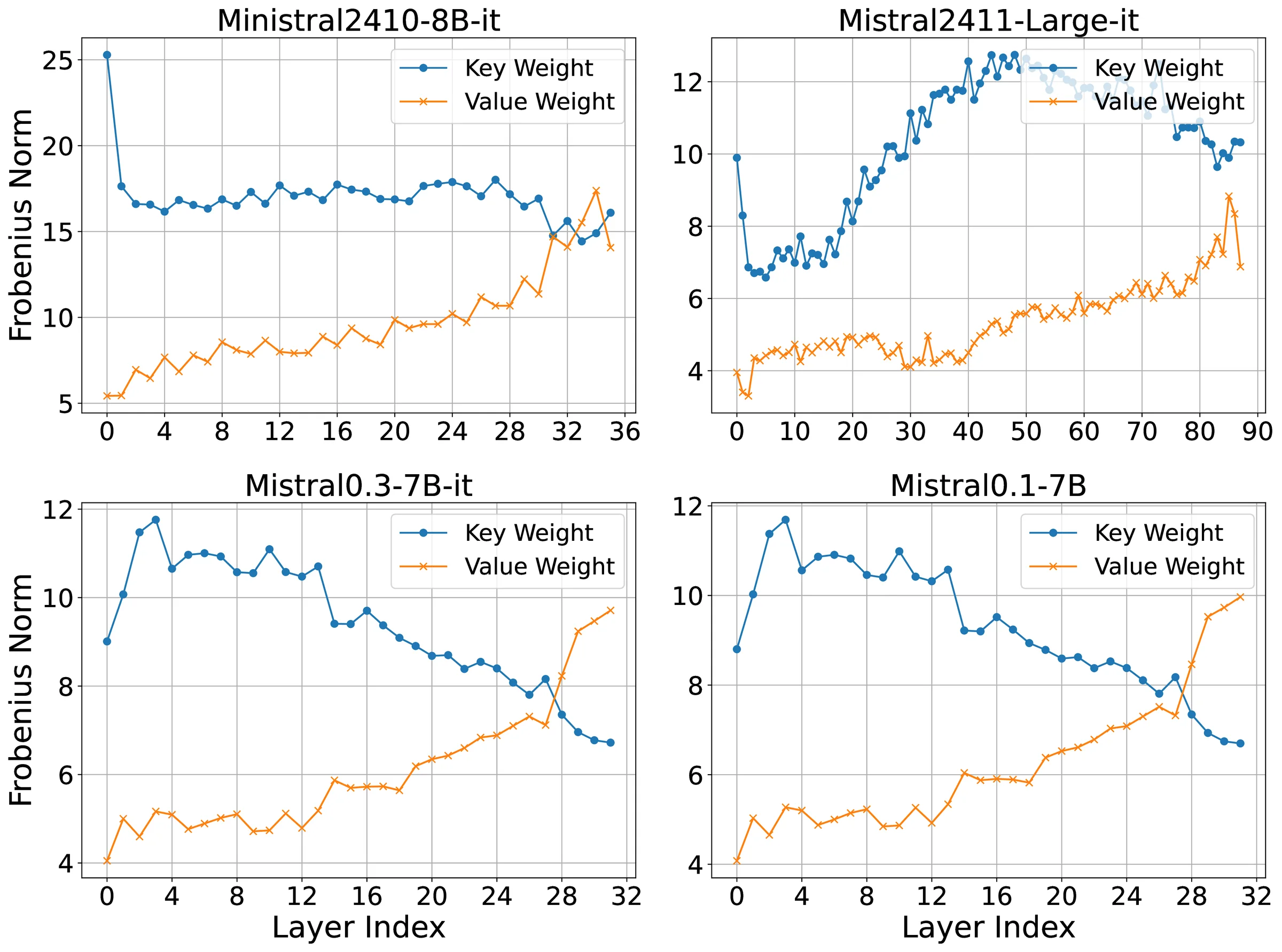
Figure 4 presents the Frobenius norms of key and value weights for the Mistral family, exhibiting the same pattern (keys consistently having higher norms than values) as shown in Figure 2 for the Llama family, further corroborating the Key-Value Norm Disparity theorem established in Section 3.1.
Singular Value Distributions
Figure ? illustrates the full-spectrum singular value distribution of key and value caches across layers of the Llama 3.3 70B model on the C4 dataset. The horizontal axis indexes singular values in descending order, starting from the largest (i.e., the spectral norm), while the vertical axis shows their magnitudes. The shaded region represents the minimum-maximum range of singular values across attention heads within each layer, and the solid curves indicate the mean singular value at each rank.
figure*[htbp]
Figures/fig5_Llama3.3-70B-it_all_L.pdf Complete singular value distribution of key and value cache for Llama 3.3-70B on the C4 dataset. The x-axis denotes the singular value indices, ordered from the largest (spectral norm) to the smallest, while the y-axis represents the corresponding magnitudes. The shaded region illustrates the range between the minimum and maximum singular values across attention heads within each layer, and the solid lines indicate the mean singular value magnitude at each index. This full-spectrum view highlights that key matrices consistently maintain significantly higher singular values throughout the entire distribution, further reinforcing their dominant representational capacity compared to value matrices.
figure*
Quantization Error
By using quantization error, we refer to evaluating how closely the quantized-then-dequantized key/value (KV) caches reconstruct their full-precision counterparts, measured as the reconstruction mean-squared error (MSE), which is exactly the Frobenius norm error normalized by the number of elements. This serves as a practical proxy for downstream quality because uniform -bit quantization admits norm-based bounds in which reconstruction error scales with the cache norm and decays roughly like ; thus, at a fixed bit budget, higher-norm caches incur larger distortion, and bit allocations that minimize reconstruction error are directly targeting the quantity most affected by quantization.
table*[htbp]
Quantization error (mean ± std) for the key and value caches ( and ) at 2-bit, 3-bit, and 4-bit quantization, evaluated on the MMLU dataset.
tabularl>0.9c c >0.9c c >0.9c c & & & & & & \ Llama3.2-1B & 4.851 gray ± 1.037 & 0.127 gray ± 0.101 & 1.037 gray ± 0.265 & 0.021 gray ± 0.015 & 0.227 gray ± 0.059 & 0.005 gray ± 0.003 \ Llama3.2-1B-it & 4.373 gray ± 1.034 & 0.124 gray ± 0.090 & 0.879 gray ± 0.218 & 0.019 gray ± 0.013 & 0.192 gray ± 0.047 & 0.004 gray ± 0.003 \ Llama3.2-3B & 3.943 gray ± 0.924 & 0.193 gray ± 0.096 & 0.849 gray ± 0.150 & 0.030 gray ± 0.015 & 0.183 gray ± 0.031 & 0.007 gray ± 0.003 \ Llama3.2-3B-it & 4.487 gray ± 1.180 & 0.202 gray ± 0.100 & 0.894 gray ± 0.180 & 0.030 gray ± 0.015 & 0.193 gray ± 0.037 & 0.007 gray ± 0.003 \ Llama2-7B & 3.190 gray ± 0.783 & 0.259 gray ± 0.184 & 0.769 gray ± 0.194 & 0.042 gray ± 0.030 & 0.168 gray ± 0.042 & 0.009 gray ± 0.006 \ Llama3.1-8B-it & 6.003 gray ± 1.782 & 0.187 gray ± 0.127 & 1.082 gray ± 0.244 & 0.028 gray ± 0.019 & 0.235 gray ± 0.055 & 0.006 gray ± 0.004 \ Llama3.3-70B-it & 4.883 gray ± 1.106 & 0.112 gray ± 0.093 & 0.942 gray ± 0.198 & 0.016 gray ± 0.012 & 0.206 gray ± 0.043 & 0.003 gray ± 0.003 \ Nemotron3.1-it & 5.125 gray ± 1.284 & 0.114 gray ± 0.094 & 0.985 gray ± 0.207 & 0.016 gray ± 0.012 & 0.216 gray ± 0.046 & 0.003 gray ± 0.003 \ Phi3-Medium-128K-it & 5.063 gray ± 1.914 & 0.584 gray ± 0.559 & 1.000 gray ± 0.319 & 0.087 gray ± 0.083 & 0.217 gray ± 0.068 & 0.019 gray ± 0.018 \ Phi4 & 5.929 gray ± 1.545 & 0.657 gray ± 0.472 & 1.306 gray ± 0.231 & 0.103 gray ± 0.070 & 0.286 gray ± 0.050 & 0.022 gray ± 0.015 \ Mistral0.3-7B & 4.718 gray ± 1.340 & 0.398 gray ± 0.405 & 0.941 gray ± 0.240 & 0.059 gray ± 0.059 & 0.206 gray ± 0.053 & 0.013 gray ± 0.013 \ Qwen2.5-14B & 5.184 gray ± 2.241 & 1.270 gray ± 1.547 & 1.005 gray ± 0.288 & 0.182 gray ± 0.221 & 0.223 gray ± 0.067 & 0.040 gray ± 0.052 \ DeepSeekR1L-8B & 5.502 gray ± 1.549 & 0.189 gray ± 0.118 & 0.955 gray ± 0.204 & 0.028 gray ± 0.017 & 0.209 gray ± 0.046 & 0.006 gray ± 0.004 \ DeepSeekR1Q-14B & 5.126 gray ± 2.375 & 1.406 gray ± 1.609 & 0.900 gray ± 0.269 & 0.198 gray ± 0.226 & 0.199 gray ± 0.062 & 0.044 gray ± 0.052 \ tabular table*
table*[htbp]
Quantization error (mean ± std) for the key and value caches ( and ) at 2-bit, 3-bit, and 4-bit quantization, evaluated on the C4 dataset.
tabularl>0.9c c >0.9c c >0.9c c & & & & & & \ Llama3.2-1B & 4.885 gray ± 1.056 & 0.207 gray ± 0.166 & 1.074 gray ± 0.289 & 0.030 gray ± 0.024 & 0.233 gray ± 0.062 & 0.006 gray ± 0.005 \ Llama3.2-1B-it & 4.524 gray ± 1.108 & 0.193 gray ± 0.137 & 0.925 gray ± 0.235 & 0.028 gray ± 0.020 & 0.201 gray ± 0.050 & 0.006 gray ± 0.005 \ Llama3.2-3B & 3.885 gray ± 0.777 & 0.282 gray ± 0.150 & 0.909 gray ± 0.168 & 0.042 gray ± 0.023 & 0.194 gray ± 0.032 & 0.009 gray ± 0.005 \ Llama3.2-3B-it & 4.135 gray ± 1.088 & 0.274 gray ± 0.137 & 0.912 gray ± 0.176 & 0.039 gray ± 0.020 & 0.195 gray ± 0.036 & 0.009 gray ± 0.004 \ Llama2-7B & 6.337 gray ± 1.710 & 0.456 gray ± 0.247 & 1.054 gray ± 0.263 & 0.071 gray ± 0.038 & 0.213 gray ± 0.052 & 0.015 gray ± 0.008 \ Llama3.1-8B-it & 6.262 gray ± 1.789 & 0.254 gray ± 0.185 & 1.128 gray ± 0.249 & 0.036 gray ± 0.026 & 0.247 gray ± 0.056 & 0.008 gray ± 0.005 \ Llama3.3-70B-it & 4.391 gray ± 1.027 & 0.121 gray ± 0.097 & 0.847 gray ± 0.175 & 0.017 gray ± 0.013 & 0.186 gray ± 0.038 & 0.004 gray ± 0.003 \ Nemotron3.1-it & 5.367 gray ± 1.332 & 0.127 gray ± 0.105 & 1.049 gray ± 0.222 & 0.018 gray ± 0.013 & 0.231 gray ± 0.049 & 0.004 gray ± 0.003 \ Phi3-Medium-128K-it & 4.831 gray ± 1.759 & 0.788 gray ± 0.726 & 1.022 gray ± 0.306 & 0.109 gray ± 0.097 & 0.220 gray ± 0.064 & 0.023 gray ± 0.021 \ Phi4 & 5.715 gray ± 1.442 & 0.850 gray ± 0.684 & 1.316 gray ± 0.245 & 0.124 gray ± 0.093 & 0.291 gray ± 0.056 & 0.027 gray ± 0.020 \ Mistral0.3-7B & 5.027 gray ± 1.332 & 0.543 gray ± 0.493 & 1.014 gray ± 0.269 & 0.079 gray ± 0.068 & 0.223 gray ± 0.060 & 0.017 gray ± 0.015 \ Qwen2.5-14B & 4.382 gray ± 2.170 & 1.544 gray ± 1.872 & 0.846 gray ± 0.250 & 0.220 gray ± 0.265 & 0.187 gray ± 0.060 & 0.048 gray ± 0.060 \ DeepSeekR1L-8B & 4.575 gray ± 1.122 & 0.204 gray ± 0.134 & 0.817 gray ± 0.141 & 0.030 gray ± 0.019 & 0.179 gray ± 0.033 & 0.006 gray ± 0.004 \ DeepSeekR1Q-14B & 4.832 gray ± 2.354 & 1.651 gray ± 1.914 & 0.927 gray ± 0.283 & 0.232 gray ± 0.267 & 0.201 gray ± 0.061 & 0.051 gray ± 0.060 \ tabular table*
table*[htbp]
Quantization error (mean ± std) for the key and value caches ( and ) at 2-bit, 3-bit, and 4-bit quantization, evaluated on the GSM8K dataset.
tabularl>0.9l l >0.9l l >0.9l l & & & & & & \ Llama3.2-1B & 5.703 gray ± 1.557 & 0.179 gray ± 0.136 & 1.213 gray ± 0.352 & 0.026 gray ± 0.020 & 0.266 gray ± 0.078 & 0.005 gray ± 0.004 \ Llama3.2-1B-it & 5.002 gray ± 1.383 & 0.171 gray ± 0.130 & 1.024 gray ± 0.287 & 0.025 gray ± 0.020 & 0.223 gray ± 0.061 & 0.006 gray ± 0.004 \ Llama3.2-3B & 4.840 gray ± 1.396 & 0.261 gray ± 0.136 & 1.045 gray ± 0.211 & 0.038 gray ± 0.021 & 0.226 gray ± 0.044 & 0.008 gray ± 0.005 \ Llama3.2-3B-it & 3.604 gray ± 0.850 & 0.226 gray ± 0.129 & 0.790 gray ± 0.135 & 0.034 gray ± 0.019 & 0.171 gray ± 0.028 & 0.007 gray ± 0.004 \ Llama2-7B & 5.081 gray ± 1.396 & 0.405 gray ± 0.231 & 0.969 gray ± 0.238 & 0.065 gray ± 0.037 & 0.205 gray ± 0.050 & 0.014 gray ± 0.008 \ Llama3.1-8B-it & 6.445 gray ± 1.837 & 0.213 gray ± 0.161 & 1.184 gray ± 0.268 & 0.030 gray ± 0.022 & 0.257 gray ± 0.060 & 0.007 gray ± 0.005 \ Llama3.3-70B-it & 4.967 gray ± 1.127 & 0.113 gray ± 0.091 & 0.978 gray ± 0.203 & 0.016 gray ± 0.012 & 0.214 gray ± 0.044 & 0.004 gray ± 0.003 \ Nemotron3.1-it & 4.752 gray ± 1.124 & 0.113 gray ± 0.089 & 0.940 gray ± 0.194 & 0.016 gray ± 0.012 & 0.206 gray ± 0.042 & 0.004 gray ± 0.003 \ Phi3-Medium-128K-it & 4.940 gray ± 1.834 & 0.605 gray ± 0.579 & 1.042 gray ± 0.320 & 0.088 gray ± 0.082 & 0.227 gray ± 0.069 & 0.019 gray ± 0.018 \ Phi4 & 6.610 gray ± 1.624 & 0.785 gray ± 0.598 & 1.498 gray ± 0.293 & 0.116 gray ± 0.082 & 0.330 gray ± 0.064 & 0.025 gray ± 0.017 \ Mistral0.3-7B & 5.308 gray ± 1.367 & 0.461 gray ± 0.434 & 1.065 gray ± 0.288 & 0.067 gray ± 0.061 & 0.232 gray ± 0.061 & 0.015 gray ± 0.013 \ Qwen2.5-14B & 4.829 gray ± 2.179 & 1.736 gray ± 2.659 & 0.979 gray ± 0.264 & 0.241 gray ± 0.372 & 0.214 gray ± 0.061 & 0.051 gray ± 0.077 \ DeepSeekR1L-8B & 5.547 gray ± 1.517 & 0.193 gray ± 0.129 & 1.000 gray ± 0.212 & 0.028 gray ± 0.018 & 0.218 gray ± 0.049 & 0.006 gray ± 0.004 \ DeepSeekR1Q-14B & 4.477 gray ± 2.176 & 1.424 gray ± 1.752 & 0.830 gray ± 0.256 & 0.200 gray ± 0.242 & 0.181 gray ± 0.058 & 0.044 gray ± 0.056 \ tabular table*
figure*[h]
subfigure0.9
Figures/fig9.1_Llama3.1-8B-it_C4_plot.pdf
C4
subfigure subfigure0.9
Figures/fig9.2_Llama3.1-8B-it_MMLU_plot.pdf MMLU
subfigure subfigure0.9
Figures/fig9.3_Llama3.1-8B-it_GSM_plot.pdf
GSM8k
subfigure
Quantization error (MSE) of key and value caches in the Llama 3.1 8B model across 32 layers for (a) C4, (b) MMLU, and (c) GSM8K. The top row shows 2-bit quantization (, ), and the bottom row shows 4-bit quantization (, ). Each point corresponds to an attention head within the respective layer. The x-axis denotes the layer index, and the y-axis indicates the quantization error (MSE).
figure*
figure*[H]
subfigure.9
Figures/fig9.1_Llama3.1-8B-it_C4_plot.pdf C4 dataset
subfigure subfigure.9
Figures/fig9.2_Llama3.1-8B-it_MMLU_plot.pdf MMLU dataset
subfigure subfigure.9
Figures/fig9.3_Llama3.1-8B-it_GSM_plot.pdf GSM8k dataset
subfigure Quantization error (MSE) of K and V caches in the Llama 3.1 8B model across 32 layers for the (a) C4, (b) MMLU, and (c) GSM8k datasets. The top row in each plot shows 2-bit quantization (k2, v2), while the bottom row shows 4-bit quantization (k4, v4). Each point represents a different attention head in the corresponding layer. The x-axis indicates the layer index, and the y-axis shows the quantization error in MSE.
figure*
Downstream Accuracy Across Quantization Precisions
Comprehensive downstream accuracy results for KV cache quantization using the HQQ backend are provided for CoQA (F1 scores), EQ-Parseable (parseable-pass rates and exact-match scores), and GSM8K (flexible and strict accuracy) in Tables ?, ?, ?, and ?, respectively.
table*[htbp]
Downstream Accuracy on CoQA (Word-Overlap F1) Across Quantization Precisions. (KxVy) denotes x-bit keys and y-bit values; higher is better. Results show the keys are the bottleneck while values can be compressed more aggressively: moving from 1-bit to 2-bit keys with values fixed at 1-bit yields large gains (e.g., Qwen3-32B: 0.2310.732; Llama-3.2-3B: 0.1280.577), whereas at fixed keys 4-bit, sweeping values from 18 bits changes F1 only marginally (e.g., Qwen3-8B (K6V1) 0.813 vs. (K6V8) 0.819; Qwen3-32B (K8V1) 0.818 vs. (K8V8) 0.827). With sufficiently precise keys (6-8 bits), even 2-bit values nearly match BF16: Llama-3.2-1B (K6V2) 0.700 vs. BF16 0.701; Qwen3-32B (K6V2) 0.826 vs. BF16 0.826. In contrast, raising values at 1-bit keys barely helps (e.g., Qwen3-4B (K1V2) 0.361 vs. (K1V8) 0.364).
tabularlccccccc & 1cQwen3 & 1cLlama-3.2 & 1cLlama-3.2 & 1cQwen3 & 1cLlama-3.1 & 1cQwen3 & 1cQwen3 \ & 0.6B & 1B & 3B & 4B & 8B & 8B & 32B \ & 0.130 & 0.148 & 0.128 & 0.222 & 0.127 & 0.359 & 0.231 \ & 0.227 & 0.236 & 0.223 & 0.361 & 0.207 & 0.384 & 0.328 \ & 0.226 & 0.237 & 0.229 & 0.376 & 0.242 & 0.386 & 0.349 \ & 0.215 & 0.243 & 0.230 & 0.379 & 0.221 & 0.379 & 0.352 \ & 0.220 & 0.240 & 0.222 & 0.364 & 0.242 & 0.382 & 0.355 \ & 0.253 & 0.190 & 0.577 & 0.464 & 0.565 & 0.599 & 0.732 \ & 0.334 & 0.526 & 0.760 & 0.721 & 0.757 & 0.767 & 0.809 \ & 0.333 & 0.559 & 0.766 & 0.732 & 0.763 & 0.761 & 0.809 \ & 0.340 & 0.565 & 0.764 & 0.730 & 0.764 & 0.766 & 0.807 \ & 0.332 & 0.568 & 0.764 & 0.733 & 0.766 & 0.770 & 0.804 \ & 0.497 & 0.575 & 0.769 & 0.803 & 0.773 & 0.815 & 0.818 \ & 0.666 & 0.693 & 0.797 & 0.806 & 0.786 & 0.822 & 0.820 \ & 0.692 & 0.701 & 0.798 & 0.807 & 0.788 & 0.819 & 0.825 \ & 0.688 & 0.702 & 0.797 & 0.809 & 0.784 & 0.817 & 0.824 \ & 0.687 & 0.700 & 0.797 & 0.807 & 0.782 & 0.818 & 0.823 \ & 0.650 & 0.597 & 0.771 & 0.801 & 0.765 & 0.813 & 0.817 \ & 0.693 & 0.700 & 0.798 & 0.803 & 0.785 & 0.821 & 0.826 \ & 0.702 & 0.705 & 0.796 & 0.807 & 0.786 & 0.821 & 0.825 \ & 0.701 & 0.706 & 0.795 & 0.808 & 0.790 & 0.819 & 0.825 \ & 0.694 & 0.703 & 0.796 & 0.807 & 0.789 & 0.819 & 0.825 \ & 0.651 & 0.599 & 0.769 & 0.802 & 0.767 & 0.815 & 0.818 \ & 0.691 & 0.696 & 0.798 & 0.803 & 0.788 & 0.823 & 0.825 \ & 0.701 & 0.704 & 0.795 & 0.807 & 0.789 & 0.821 & 0.826 \ & 0.699 & 0.705 & 0.795 & 0.809 & 0.787 & 0.819 & 0.826 \ & 0.697 & 0.704 & 0.795 & 0.808 & 0.786 & 0.821 & 0.827 \ BF16 & 0.708 & 0.701 & 0.795 & 0.808 & 0.785 & 0.820 & 0.826 \ tabular table*
table*[htbp]
Downstream Accuracy on EQ-Bench parseable Across Quantization Precisions. (KxVy) denotes x-bit keys and y-bit values; the higher the value, the better. Parseable accuracy is the share of prompts where the model's output follows the required structured format so the scorer can automatically extract the four 0-10 emotion ratings. Results consistently show that keys are the bottleneck, while values can be compressed more aggressively. With 1-bit keys, outputs are never parseable across all models regardless of value precision ((K1Vy=0) everywhere). Upgrading to 2-bit keys yields large jumps even with very low-precision values. For instance, Llama-3.2-3B rises from 0 to 80.702 at (K2V2), Llama-3.1-8B from 0 to 85.965, and Qwen3-32B from 0 to 67.836, while further increasing values from 28 bits at fixed (K=2) brings only modest gains (e.g., Llama-3.2-3B 80.70284.211, Llama-3.1-8B 85.96590.059, Qwen3-8B 65.49768.421). Once keys are 4-6 bits, even 1-2-bit values nearly saturate parseability and often match or exceed BF16 (e.g., Qwen3-8B (K4V1) 98.830 vs. BF16 94.737; Qwen3-32B (K6V1) 79.532 BF16 79.532; Llama-3.2-1B (K6V2) 97.076 vs. BF16 97.661).
tabularlccccccc & 1cQwen3 & 1cLlama-3.2 & 1cLlama-3.2 & 1cQwen3 & 1cLlama-3.1 & 1cQwen3 & 1cQwen3 \ & 0.6B & 1B & 3B & 4B & 8B & 8B & 32B \ & 0 & 0 & 0 & 0 & 0 & 0 & 0 \ & 0 & 0 & 0 & 0 & 0 & 0 & 0 \ & 0 & 0 & 0 & 0 & 0 & 0 & 0 \ & 0 & 0 & 0 & 0 & 0 & 0 & 0 \ & 0 & 0 & 0 & 0 & 0 & 0 & 0 \ & 0 & 0 & 8.187 & 0 & 35.673 & 0 & 2.339 \ & 0 & 16.374 & 80.702 & 27.485 & 85.965 & 65.497 & 67.836 \ & 0 & 34.503 & 84.795 & 39.766 & 88.889 & 70.175 & 70.175 \ & 0 & 39.181 & 83.041 & 36.842 & 90.059 & 67.836 & 69.591 \ & 0 & 38.012 & 84.211 & 40.936 & 88.889 & 68.421 & 70.760 \ & 0 & 47.953 & 58.480 & 77.778 & 83.626 & 98.830 & 77.778 \ & 63.743 & 97.076 & 95.322 & 87.719 & 97.661 & 95.322 & 80.702 \ & 65.497 & 97.076 & 98.830 & 84.795 & 99.415 & 95.322 & 80.702 \ & 64.328 & 97.076 & 98.830 & 85.380 & 98.830 & 93.567 & 80.702 \ & 62.573 & 97.076 & 98.830 & 84.795 & 98.830 & 93.567 & 80.702 \ & 23.392 & 60.234 & 53.801 & 81.287 & 90.643 & 96.491 & 79.532 \ & 99.415 & 97.076 & 94.737 & 87.719 & 97.661 & 94.737 & 80.702 \ & 99.415 & 97.661 & 99.415 & 87.135 & 98.830 & 95.906 & 80.702 \ & 99.415 & 97.661 & 98.830 & 86.550 & 98.830 & 96.491 & 80.702 \ & 99.415 & 97.661 & 98.830 & 87.135 & 98.830 & 97.661 & 80.702 \ & 26.901 & 60.234 & 56.725 & 78.947 & 92.983 & 97.076 & 77.193 \ & 99.415 & 97.076 & 94.737 & 87.135 & 97.661 & 96.491 & 79.532 \ & 99.415 & 97.661 & 99.415 & 87.719 & 98.830 & 95.322 & 80.702 \ & 99.415 & 97.661 & 99.415 & 86.550 & 98.830 & 95.906 & 80.702 \ & 99.415 & 97.661 & 99.415 & 86.550 & 98.830 & 95.906 & 80.702 \ BF16 & 100 & 97.661 & 99.415 & 87.719 & 98.830 & 94.737 & 79.532 \ tabular table*
table*[htbp]
Downstream Accuracy on GSM8K (Flexible) Across Quantization Precisions. (KxVy) denotes x-bit keys and y-bit values; the higher the value, the better. Flexible accuracy counts a prediction as correct if the gold final numeric answer appears anywhere in the model’s output (ignoring extra formatting), rather than requiring an isolated exact-match box. Results consistently show that keys are the bottleneck, while values can be compressed more aggressively. With 1-bit keys, performance is essentially zero across all models (max ). Upgrading to 2-bit keys yields large jumps even with low-precision values—for example, Llama-3.2-3B rises from (0.015) at (K1V2) to at (K2V2), Llama-3.1-8B from (0.020) to , and Qwen3-32B from (0.018) to . At fixed K(6), even 2-bit values already match or beat BF16 (e.g., Qwen3-8B (K6V2) vs. BF16 ; Llama-3.1-8B vs. ; Qwen3-4B vs. ), and increasing values from (28) bits yields only modest gains (Llama-3.2-3B (), Qwen3-8B ()). In several cases, quantized caches even exceed BF16 (e.g., Qwen3-8B (K6V8) 0.877; Llama-3.2-3B (K4V6) 0.663; Qwen3-32B (K4V1) 0.603).
tabularlccccccc & 1cQwen3 & 1cLlama-3.2 & 1cLlama-3.2 & 1cQwen3 & 1cLlama-3.1 & 1cQwen3 & 1cQwen3 \ & 0.6B & 1B & 3B & 4B & 8B & 8B & 32B \ & 0.011 & 0.012 & 0.016 & 0.010 & 0.016 & 0.011 & 0.020 \ & 0.008 & 0.014 & 0.015 & 0.010 & 0.020 & 0.013 & 0.018 \ & 0.009 & 0.020 & 0.025 & 0.014 & 0.020 & 0.008 & 0.011 \ & 0.010 & 0.011 & 0.027 & 0.017 & 0.020 & 0.008 & 0.016 \ & 0.008 & 0.015 & 0.028 & 0.009 & 0.015 & 0.014 & 0.011 \ & 0.003 & 0.018 & 0.015 & 0.008 & 0.050 & 0.013 & 0.014 \ & 0.003 & 0.029 & 0.278 & 0.027 & 0.385 & 0.129 & 0.385 \ & 0.003 & 0.020 & 0.351 & 0.043 & 0.455 & 0.171 & 0.434 \ & 0.004 & 0.026 & 0.344 & 0.040 & 0.446 & 0.169 & 0.419 \ & 0.004 & 0.028 & 0.355 & 0.035 & 0.460 & 0.167 & 0.449 \ & 0.023 & 0.073 & 0.281 & 0.577 & 0.517 & 0.779 & 0.721 \ & 0.040 & 0.294 & 0.639 & 0.808 & 0.757 & 0.877 & 0.649 \ & 0.040 & 0.333 & 0.653 & 0.830 & 0.778 & 0.877 & 0.629 \ & 0.055 & 0.332 & 0.668 & 0.832 & 0.763 & 0.881 & 0.619 \ & 0.042 & 0.341 & 0.658 & 0.826 & 0.758 & 0.878 & 0.632 \ & 0.093 & 0.096 & 0.308 & 0.632 & 0.522 & 0.795 & 0.701 \ & 0.368 & 0.312 & 0.644 & 0.830 & 0.762 & 0.880 & 0.598 \ & 0.405 & 0.334 & 0.654 & 0.837 & 0.770 & 0.878 & 0.610 \ & 0.420 & 0.337 & 0.663 & 0.844 & 0.772 & 0.884 & 0.596 \ & 0.414 & 0.342 & 0.665 & 0.841 & 0.771 & 0.886 & 0.608 \ & 0.088 & 0.096 & 0.304 & 0.637 & 0.530 & 0.798 & 0.708 \ & 0.390 & 0.313 & 0.647 & 0.826 & 0.750 & 0.882 & 0.606 \ & 0.416 & 0.340 & 0.660 & 0.832 & 0.770 & 0.875 & 0.621 \ & 0.419 & 0.342 & 0.667 & 0.843 & 0.767 & 0.880 & 0.608 \ & 0.413 & 0.334 & 0.666 & 0.843 & 0.759 & 0.880 & 0.603 \ BF16 & 0.412 & 0.328 & 0.663 & 0.845 & 0.760 & 0.877 & 0.603 \ tabular table*
table*[htbp]
Downstream Accuracy on GSM8K (Strict) Across Quantization Precisions. (KxVy) denotes x-bit keys and y-bit values; higher is better. Same dataset as tab:gsm8k_accuracies_flexible_full, but Strict accuracy only counts a prediction as correct when the scorer can extract a single final numeric answer that exactly matches the gold. As with the Flexible metric, keys are the bottleneck, while values can be compressed more aggressively. With 1-bit keys, accuracy is essentially zero across all models (max ). Upgrading to 2-bit keys yields large jumps even with low-precision values—for example, Llama-3.2-3B rises from (0) to at (K2V2), Llama-3.1-8B from (0) to , and Qwen3-32B from (0) to . Once keys are 4-6 bits, even 2-bit values are near or above BF16 (e.g., Qwen3-8B (K6V2) vs. BF16 ; Llama-3.2-3B (K8V6) ; Qwen3-32B (K8V6) ). At fixed high key precision, increasing values from (28) bits brings only modest gains (e.g., Qwen3-8B at (K): (); Llama-3.2-3B at (K): ()).
tabularlccccccc & 1cQwen3 & 1cLlama-3.2 & 1cLlama-3.2 & 1cQwen3 & 1cLlama-3.1 & 1cQwen3 & 1cQwen3 \ & 0.6B & 1B & 3B & 4B & 8B & 8B & 32B \ & 0.000 & 0.000 & 0.000 & 0.000 & 0.000 & 0.000 & 0.000 \ & 0.000 & 0.000 & 0.000 & 0.000 & 0.000 & 0.000 & 0.000 \ & 0.000 & 0.000 & 0.000 & 0.000 & 0.000 & 0.000 & 0.000 \ & 0.000 & 0.000 & 0.002 & 0.000 & 0.000 & 0.001 & 0.000 \ & 0.000 & 0.000 & 0.000 & 0.000 & 0.000 & 0.000 & 0.000 \ & 0.000 & 0.001 & 0.005 & 0.000 & 0.028 & 0.000 & 0.002 \ & 0.000 & 0.011 & 0.276 & 0.004 & 0.380 & 0.067 & 0.234 \ & 0.000 & 0.010 & 0.350 & 0.009 & 0.444 & 0.104 & 0.334 \ & 0.000 & 0.012 & 0.344 & 0.010 & 0.439 & 0.115 & 0.330 \ & 0.000 & 0.014 & 0.353 & 0.005 & 0.449 & 0.109 & 0.347 \ & 0.006 & 0.061 & 0.293 & 0.647 & 0.500 & 0.785 & 0.701 \ & 0.042 & 0.297 & 0.628 & 0.825 & 0.751 & 0.876 & 0.726 \ & 0.044 & 0.331 & 0.643 & 0.844 & 0.759 & 0.876 & 0.734 \ & 0.055 & 0.331 & 0.657 & 0.839 & 0.748 & 0.880 & 0.733 \ & 0.049 & 0.342 & 0.649 & 0.835 & 0.745 & 0.877 & 0.737 \ & 0.083 & 0.083 & 0.326 & 0.698 & 0.506 & 0.803 & 0.702 \ & 0.369 & 0.308 & 0.639 & 0.839 & 0.750 & 0.879 & 0.709 \ & 0.405 & 0.334 & 0.644 & 0.845 & 0.756 & 0.876 & 0.719 \ & 0.422 & 0.335 & 0.656 & 0.853 & 0.751 & 0.882 & 0.717 \ & 0.414 & 0.341 & 0.657 & 0.848 & 0.753 & 0.885 & 0.721 \ & 0.085 & 0.084 & 0.324 & 0.704 & 0.513 & 0.805 & 0.695 \ & 0.388 & 0.314 & 0.640 & 0.829 & 0.739 & 0.882 & 0.717 \ & 0.417 & 0.340 & 0.652 & 0.845 & 0.756 & 0.875 & 0.721 \ & 0.419 & 0.340 & 0.661 & 0.848 & 0.749 & 0.879 & 0.723 \ & 0.415 & 0.332 & 0.660 & 0.851 & 0.744 & 0.876 & 0.723 \ BF16 & 0.413 & 0.328 & 0.657 & 0.852 & 0.741 & 0.874 & 0.718 \ tabular table*
Rotation and Grouping Results
Tables 1-4 present the full set of downstream evaluation results for integrating rotation-based outlier redistribution with mixed-precision KV quantization across multiple models and tasks, including GSM8K (flexible and strict exact match), CoQA (F1), and CoQA (exact match). Each table reports accuracy for four key-value bit allocations (, , , ) under four Rotations: none, key-only, value-only, and both key and value. The group size is fixed at 64 for both keys and values in these experiments to isolate the effect of rotation.
The results reveal several consistent trends across model scales and tasks. First, applying rotation to keys consistently improves performance at lower bit-widths ( and ), significantly narrowing the gap to higher-precision baselines. In contrast, rotating values alone yields marginal or even negative effects, especially at low precisions. Notably, applying rotation to keys only under the configuration achieves accuracy that closely matches the full baseline, indicating that the dominant benefits of rotation stem from mitigating key outliers rather than value outliers. Applying rotation to both keys and values provides little additional gain beyond key-only rotation, reinforcing that keys are the primary target for rotation-based improvements.
Figure ? examines the effect of group size configuration under a fixed mixed-precision setting without rotation. Group size () determines the block granularity of quantization: smaller groups offer finer scaling at the cost of increased metadata and computation. The results reveal a clear asymmetry between keys and values. Reducing group size for keys consistently improves downstream accuracy across CoQA, GSM8K, EQ-Bench, and LongBench, with achieving the best overall performance. This reflects the higher sensitivity of key caches to quantization distortion. In contrast, increasing value group size to 64 or 128 has a negligible impact on accuracy while reducing overhead, consistent with their lower sensitivity.
Together, these findings provide practical guidance for combining geometry-driven bit allocation with rotation and grouping strategies: rotation should primarily target keys, while keys benefit from finer group granularity and higher precision; values, on the other hand, can use coarser grouping and lower precision with minimal accuracy loss.
| Model | Rotation | ||||
|---|---|---|---|---|---|
| 4*Llama | |||||
| 3.1-8B | K+V | 52.99 | 55.80 | 76.50 | 76.95 |
| K only | 52.92 | 57.32 | 75.44 | 76.50 | |
| V only | 20.70 | 25.70 | 75.28 | 76.95 | |
| none | 18.65 | 24.41 | 75.21 | 76.95 | |
| 4*Llama | |||||
| 3.2-1B | K+V | 1.97 | 2.43 | 30.93 | 33.13 |
| K only | 2.05 | 3.03 | 28.43 | 33.13 | |
| V only | 2.05 | 1.29 | 28.58 | 29.57 | |
| none | 1.82 | 2.20 | 27.22 | 29.57 | |
| 4*Llama | |||||
| 3.2-3B | K+V | 40.11 | 44.12 | 62.85 | 64.37 |
| K only | 38.06 | 45.26 | 61.18 | 63.91 | |
| V only | 16.60 | 19.26 | 63.46 | 63.91 | |
| none | 14.86 | 21.08 | 62.93 | 63.53 | |
| 4*Qwen | |||||
| 0.6B | K+V | 0.76 | 0.61 | 37.83 | 36.47 |
| K only | 1.52 | 1.06 | 36.92 | 37.68 | |
| V only | 1.52 | 1.67 | 1.36 | 2.12 | |
| none | 0.83 | 1.90 | 1.36 | 2.05 | |
| 4*Qwen | |||||
| 32B | K+V | 31.69 | 33.81 | 66.49 | 64.22 |
| K only | 30.10 | 33.51 | 63.99 | 65.28 | |
| V only | 6.90 | 11.07 | 65.81 | 63.68 | |
| none | 6.67 | 10.92 | 64.82 | 63.76 | |
| 4*Qwen | |||||
| 4B | K+V | 0.91 | 0.76 | 83.78 | 85.37 |
| K only | 1.14 | 0.68 | 82.26 | 84.76 | |
| V only | 0.83 | 1.14 | 82.56 | 83.70 | |
| none | 1.14 | 0.83 | 81.80 | 83.40 | |
| 4*Qwen | |||||
| 8B | K+V | 29.34 | 36.01 | 88.17 | 88.17 |
| K only | 29.57 | 35.56 | 87.64 | 87.95 | |
| V only | 1.97 | 1.21 | 86.73 | 87.34 | |
| none | 2.27 | 1.67 | 86.58 | 88.02 |
| Model | Rotation | ||||
|---|---|---|---|---|---|
| 4*Llama | |||||
| 3.1-8B | K+V | 51.71 | 55.27 | 74.37 | 74.45 |
| K only | 51.93 | 56.48 | 73.24 | 73.92 | |
| V only | 19.33 | 24.49 | 73.01 | 74.60 | |
| none | 17.97 | 22.74 | 72.93 | 74.60 | |
| 4*Llama | |||||
| 3.2-1B | K+V | 0.83 | 1.21 | 31.01 | 32.98 |
| K only | 0.68 | 1.29 | 29.04 | 33.06 | |
| V only | 0.38 | 0.61 | 28.51 | 29.57 | |
| none | 0.45 | 0.61 | 27.22 | 29.34 | |
| 4*Llama | |||||
| 3.2-3B | K+V | 39.65 | 43.67 | 61.94 | 63.84 |
| K only | 36.47 | 44.96 | 60.27 | 63.46 | |
| V only | 16.00 | 19.26 | 63.00 | 63.38 | |
| none | 14.40 | 21.00 | 62.02 | 62.85 | |
| 4*Qwen | |||||
| 0.6B | K+V | 0.00 | 0.00 | 38.14 | 36.92 |
| K only | 0.00 | 0.00 | 37.38 | 37.83 | |
| V only | 0.00 | 0.00 | 0.15 | 0.53 | |
| none | 0.00 | 0.00 | 0.30 | 0.08 | |
| 4*Qwen | |||||
| 32B | K+V | 21.99 | 28.35 | 74.75 | 75.59 |
| K only | 21.46 | 26.38 | 74.75 | 75.28 | |
| V only | 2.20 | 5.00 | 74.00 | 75.13 | |
| none | 1.52 | 4.93 | 73.77 | 74.37 | |
| 4*Qwen | |||||
| 4B | K+V | 0.23 | 0.08 | 84.53 | 85.60 |
| K only | 0.00 | 0.08 | 83.40 | 84.99 | |
| V only | 0.00 | 0.00 | 82.49 | 83.70 | |
| none | 0.00 | 0.08 | 81.80 | 83.78 | |
| 4*Qwen | |||||
| 8B | K+V | 25.32 | 30.33 | 87.72 | 87.87 |
| K only | 25.17 | 32.15 | 87.49 | 87.34 | |
| V only | 0.15 | 0.00 | 86.43 | 86.88 | |
| none | 0.00 | 0.08 | 86.50 | 87.41 |
| Model | Rotation | ||||
|---|---|---|---|---|---|
| 4*Llama | |||||
| 3.1-8B | K+V | 77.70 | 77.83 | 78.88 | 78.45 |
| K only | 77.39 | 78.10 | 77.93 | 78.75 | |
| V only | 75.46 | 76.71 | 79.34 | 78.76 | |
| none | 74.72 | 76.57 | 78.10 | 79.18 | |
| 4*Llama | |||||
| 3.2-1B | K+V | 50.66 | 53.55 | 70.44 | 70.47 |
| K only | 50.18 | 53.46 | 69.40 | 70.27 | |
| V only | 39.50 | 44.93 | 69.58 | 70.52 | |
| none | 38.82 | 44.33 | 69.53 | 70.31 | |
| 4*Llama | |||||
| 3.2-3B | K+V | 78.45 | 78.78 | 79.24 | 79.13 |
| K only | 78.24 | 78.88 | 78.71 | 79.20 | |
| V only | 73.25 | 74.48 | 78.86 | 79.27 | |
| none | 74.10 | 74.55 | 79.14 | 79.37 | |
| 4*Qwen | |||||
| 0.6B | K+V | 33.99 | 34.06 | 68.92 | 70.09 |
| K only | 33.88 | 33.70 | 69.62 | 70.08 | |
| V only | 29.00 | 27.39 | 48.19 | 48.06 | |
| none | 28.89 | 28.04 | 46.49 | 48.41 | |
| 4*Qwen | |||||
| 32B | K+V | 64.85 | 67.39 | 82.46 | 82.59 |
| K only | 67.16 | 67.18 | 82.62 | 82.55 | |
| V only | 77.82 | 78.55 | 82.35 | 82.50 | |
| none | 76.80 | 78.35 | 82.60 | 82.77 | |
| 4*Qwen | |||||
| 4B | K+V | 62.43 | 63.82 | 80.16 | 80.56 |
| K only | 62.09 | 64.35 | 80.46 | 80.63 | |
| V only | 56.73 | 59.26 | 80.07 | 80.16 | |
| none | 54.93 | 59.68 | 80.41 | 80.19 | |
| 4*Qwen | |||||
| 8B | K+V | 79.33 | 79.65 | 82.32 | 81.98 |
| K only | 78.27 | 79.89 | 81.15 | 82.09 | |
| V only | 67.51 | 70.41 | 82.23 | 82.01 | |
| none | 66.86 | 69.83 | 81.49 | 81.99 |
| Model | Rotation | ||||
|---|---|---|---|---|---|
| 4*Llama | |||||
| 3.1-8B | K+V | 62.43 | 63.37 | 63.25 | 63.40 |
| K only | 62.12 | 63.32 | 63.03 | 63.65 | |
| V only | 58.13 | 60.12 | 64.48 | 63.75 | |
| none | 58.12 | 59.65 | 62.92 | 64.45 | |
| 4*Llama | |||||
| 3.2-1B | K+V | 33.38 | 37.87 | 54.78 | 56.02 |
| K only | 33.72 | 37.30 | 54.22 | 55.32 | |
| V only | 25.47 | 30.37 | 53.97 | 55.65 | |
| none | 24.42 | 30.23 | 54.30 | 55.45 | |
| 4*Llama | |||||
| 3.2-3B | K+V | 62.47 | 62.28 | 62.83 | 63.40 |
| K only | 62.12 | 62.72 | 62.93 | 63.53 | |
| V only | 56.07 | 57.48 | 62.70 | 63.73 | |
| none | 56.45 | 57.62 | 63.42 | 63.77 | |
| 4*Qwen | |||||
| 0.6B | K+V | 19.67 | 19.57 | 56.07 | 56.73 |
| K only | 18.72 | 18.18 | 55.53 | 56.73 | |
| V only | 13.97 | 14.27 | 28.18 | 28.17 | |
| none | 14.25 | 13.80 | 28.22 | 28.82 | |
| 4*Qwen | |||||
| 32B | K+V | 46.97 | 49.95 | 70.18 | 70.77 |
| K only | 50.28 | 49.42 | 70.48 | 70.87 | |
| V only | 61.77 | 64.08 | 70.02 | 70.37 | |
| none | 61.12 | 63.92 | 69.90 | 70.50 | |
| 4*Qwen | |||||
| 4B | K+V | 41.28 | 42.45 | 65.68 | 66.28 |
| K only | 41.65 | 43.45 | 66.40 | 66.47 | |
| V only | 39.22 | 40.03 | 65.43 | 66.20 | |
| none | 37.70 | 40.22 | 65.52 | 66.07 | |
| 4*Qwen | |||||
| 8B | K+V | 61.70 | 61.88 | 68.55 | 67.73 |
| K only | 60.07 | 62.40 | 66.62 | 68.23 | |
| V only | 49.62 | 51.58 | 68.10 | 68.07 | |
| none | 48.40 | 51.65 | 67.07 | 68.00 |
figure*
Figures/group_size_comparison_bars.pdf Effect of group size configurations on downstream accuracy. Each bar shows performance on CoQA, GSM8K, EQ-Bench, and LongBench for different key-value grouping combinations () under the mixed-precision setting. Smaller group sizes for keys consistently improve accuracy across all tasks, while value group size has a smaller but non-negligible effect. Configurations with achieve the best overall performance, highlighting the benefit of finer quantization granularity for key caches, which are more sensitive to quantization distortion. In contrast, larger group sizes for values ( or ) preserve performance while reducing overhead, aligning with their lower sensitivity.
figure*
table*[htbp]
\arraystretch1.3
Performance by rotation strategy across tasks. Values report the mean performance across seven models (0.6B–32B parameters) and four quantization configurations (, , , ). The values indicate the variability range across model scales and quantization settings, with larger ranges reflecting higher sensitivity to these factors.
\linewidth! tabularllcccc Task & Metric & No Rotation & Value-Only & Key-Only & Both \ CoQa & Exact Match & & & & \ Eq Bench & Parseable & & & & \ GSM8K & Exact Match & & & & \ Longbench & ROUGE Score & & & & \ tabular
table*
Reproducibility and Resources
Inference was performed using the Hugging Face Transformers [57] and Accelerate [58] with FlashAttention [59, 60]. We integrated both Quanto and HQQ into the Language Model Evaluation Harness [61] to enable systematic and reproducible evaluation of model performance under varying quantization schemes. Quantization error is measured by MSE, and confidence intervals use Bayesian variance. [62]. Evaluations were executed on two High-performance Computing (HPC) clusters, detailed in Table ?.
table*[htbp] Specifications of Two High-Performance Computing (HPC) Clusters Used in This Study
\arraystretch1.2 tabular@lcc@ Cluster & Cluster A & Cluster B \ Processor & AMD EPYC 7742 2 & Intel Xeon Platinum 8468 2 \ RAM & 2048GB & 2048GB \ GPU & NVIDIA A100 8 & NVIDIA H200 8 \ VRAM & 80GB HBM2e & 141GB HBM3e \ Scale & 5 nodes (40 A100) & 5 nodes (40 H200) \ tabular table*
Appendix
References
- Attention Is All You Need. Proceedings of the 31st Conference on Neural Information Processing Systems (NeurIPS 2017). 2017. https://arxiv.org/abs/1706.03762
- Sequence to Sequence Learning with Neural Networks. Proceedings of the 27th Conference on Neural Information Processing Systems (NeurIPS 2014). 2014. https://arxiv.org/abs/1409.3215
- Improving Language Understanding by Generative Pre-Training. misc. 2018. https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
- Language Models are Unsupervised Multitask Learners. OpenAI. 2019. https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
- Language Models are Few-Shot Learners. Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020). 2020. https://arxiv.org/abs/2005.14165
- GPT-4 Technical Report. misc. 2024. https://arxiv.org/abs/2303.08774
- The Llama 4 Herd: The Beginning of a New Era of Natively Multimodal Intelligence. misc. 2025. https://ai.meta.com/blog/llama-4-multimodal-intelligence/
- Large Enough: Announcing Mistral Large 2. misc. 2024. https://mistral.ai/news/mistral-large-2407
- DeepSeek-V3 Technical Report. misc. 2025. https://arxiv.org/abs/2412.19437
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Proceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS 2022). 2022. https://arxiv.org/abs/2201.11903
- FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU. Proceedings of the 40th International Conference on Machine Learning. 2023. https://proceedings.mlr.press/v202/sheng23a.html
- Gemini 2.0 Flash. misc. 2025. https://cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/2-0-flash
- OpenAI O1 System Card. misc. 2024. https://cdn.openai.com/o1-system-card.pdf
- OpenAI O3-mini. misc. 2025. https://openai.com/index/openai-o3-mini/
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. misc. 2025. https://arxiv.org/abs/2501.12948
- The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation. misc. 2025.
- Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. Proceedings of the International Conference on Learning Representations (ICLR 2016). 2016. https://arxiv.org/abs/1510.00149
- A White Paper on Neural Network Quantization. misc. 2021. https://arxiv.org/abs/2106.08295
- A Survey of Quantization Methods for Efficient Neural Network Inference. misc. 2021. https://arxiv.org/abs/2103.13630
- GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers. Proceedings of the International Conference on Learning Representations (ICLR 2023). 2023. https://arxiv.org/abs/2210.17323
- Optimal Brain Compression: A Framework for Accurate Post-Training Quantization and Pruning. Proceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS 2022). 2023. https://arxiv.org/abs/2208.11580
- AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration. Proceedings of the 7th MLSys Conference 2024. 2024. https://arxiv.org/abs/2306.00978
- LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale. misc. 2022. https://arxiv.org/abs/2208.07339
- SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models. Proceedings of the 40th International Conference on Machine Learning (ICML 2023). 2023. https://arxiv.org/abs/2211.10438
- OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models. Proceedings of the International Conference on Learning Representations (ICLR 2024). 2024. https://arxiv.org/abs/2308.13137
- Efficiently Scaling Transformer Inference. Proceedings of the 6th MLSys Conference 2023. 2023. https://www.arxiv.org/abs/2211.05102
- WKVQuant: Quantizing Weight and Key/Value Cache for Large Language Models Gains More. misc. 2024. https://arxiv.org/abs/2402.12065
- A Survey on Large Language Model Acceleration based on KV Cache Management. misc. 2025. https://arxiv.org/abs/2412.19442
- ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers. Proceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS 2022). 2022. https://arxiv.org/abs/2206.01861
- FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU. Proceedings of the 40th International Conference on Machine Learning (ICML 2023). 2023. https://arxiv.org/abs/2303.06865
- KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache. Proceedings of the 41st International Conference on Machine Learning (ICML 2024). 2024. https://arxiv.org/abs/2402.02750
- KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization. Proceedings of the 38th Conference on Neural Information Processing Systems (NeurIPS 2024). 2024. https://arxiv.org/abs/2401.18079
- SnapKV: LLM Knows What You are Looking for Before Generation. Proceedings of the 38th Conference on Neural Information Processing Systems (NeurIPS 2024). 2024. https://arxiv.org/abs/2404.14469
- QAQ: Quality Adaptive Quantization for LLM KV Cache. misc. 2024. https://arxiv.org/abs/2403.04643
- SKVQ: Sliding-window Key and Value Cache Quantization for Large Language Models. Proceedings of COLM 2024. 2024. https://arxiv.org/abs/2405.06219
- CSR:Achieving 1 Bit Key-Value Cache via Sparse Representation. misc. 2024. https://arxiv.org/abs/2412.11741
- KVTuner: Sensitivity-Aware Layer-wise Mixed Precision KV Cache Quantization for Efficient and Nearly Lossless LLM Inference. misc. 2025. https://arxiv.org/abs/2502.04420
- H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models. Thirty-seventh Conference on Neural Information Processing Systems. 2023. https://openreview.net/forum?id=RkRrPp7GKO
- PM-KVQ: Progressive Mixed-precision KV Cache Quantization for Long-CoT LLMs. misc. 2025. https://arxiv.org/abs/2505.18610
- No Token Left Behind: Reliable KV Cache Compression via Importance-Aware Mixed Precision Quantization. misc. 2024. https://arxiv.org/abs/2402.18096
- Understanding the difficulty of training deep feedforward neural networks. Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics. 2010. https://proceedings.mlr.press/v9/glorot10a.html
- A Mathematical Framework for Transformer Circuits. Transformer Circuits Thread. 2021. https://transformer-circuits.pub/2021/framework/index.html
- Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus. misc. 2021. https://arxiv.org/abs/2104.08758
- Measuring Massive Multitask Language Understanding. Proceedings of the International Conference on Learning Representations (ICLR 2021). 2021. https://arxiv.org/abs/2009.03300
- Training Verifiers to Solve Math Word Problems. misc. 2021. https://arxiv.org/abs/2110.14168
- The Llama 3 Herd of Models. misc. 2024. https://arxiv.org/abs/2407.21783
- Phi-4 Technical Report. misc. 2024. https://arxiv.org/abs/2412.08905
- Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone. misc. 2024. https://arxiv.org/abs/2404.14219
- Nemotron-4 340B Technical Report. misc. 2024. https://arxiv.org/abs/2406.11704
- Half-Quadratic Quantization of Large Machine Learning Models. misc. 2023. https://mobiusml.github.io/hqq_blog/
- Qwen3: Think Deeper, Act Faster. misc. 2025. https://qwenlm.github.io/blog/qwen3/
- Flash-Decoding for long-context inference. misc. 2023. https://crfm.stanford.edu/2023/10/12/flashdecoding.html
- MARLIN: Mixed-Precision Auto-Regressive Parallel Inference on Large Language Models. Proceedings of the 30th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming. 2025. https://doi.org/10.1145/3710848.3710871
- CoQA: A Conversational Question Answering Challenge. misc. 2019. https://arxiv.org/abs/1808.07042
- EQ-Bench: An Emotional Intelligence Benchmark for Large Language Models. misc. 2024. https://arxiv.org/abs/2312.06281
- Quarot: Outlier-free 4-bit inference in rotated llms. Advances in Neural Information Processing Systems. 2024.
- Transformers: State-of-the-Art Natural Language Processing. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2020. https://www.aclweb.org/anthology/2020.emnlp-demos.6
- Accelerate: Training and inference at scale made simple, efficient and adaptable.. misc. 2022. https://github.com/huggingface/accelerate
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. Advances in Neural Information Processing Systems (NeurIPS). 2022.
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. International Conference on Learning Representations (ICLR). 2024.
- The Language Model Evaluation Harness. Zenodo. 2024. https://zenodo.org/records/12608602
- Don't Pass@k: A Bayesian Framework for Large Language Model Evaluation. arXiv preprint arXiv:2510.04265. 2025.