Lossy compression is a gamble
- Quantization loses accuracy: 8-bit SmoothQuant drops DeepSeek-R1-Distill-Qwen-1.5B reasoning by 9.09%.
- Behavior shifts at equal accuracy: 6.37% of GSM8K answers flip under W8A16 GPTQ.
- Prior lossless coders (ZipNN, NeuZip) shrink checkpoints but barely speed up GPU inference.
DFloat11 is lossless: outputs are bit-for-bit identical, so there is nothing to stress-test per deployment.
BFloat16's exponent is almost empty
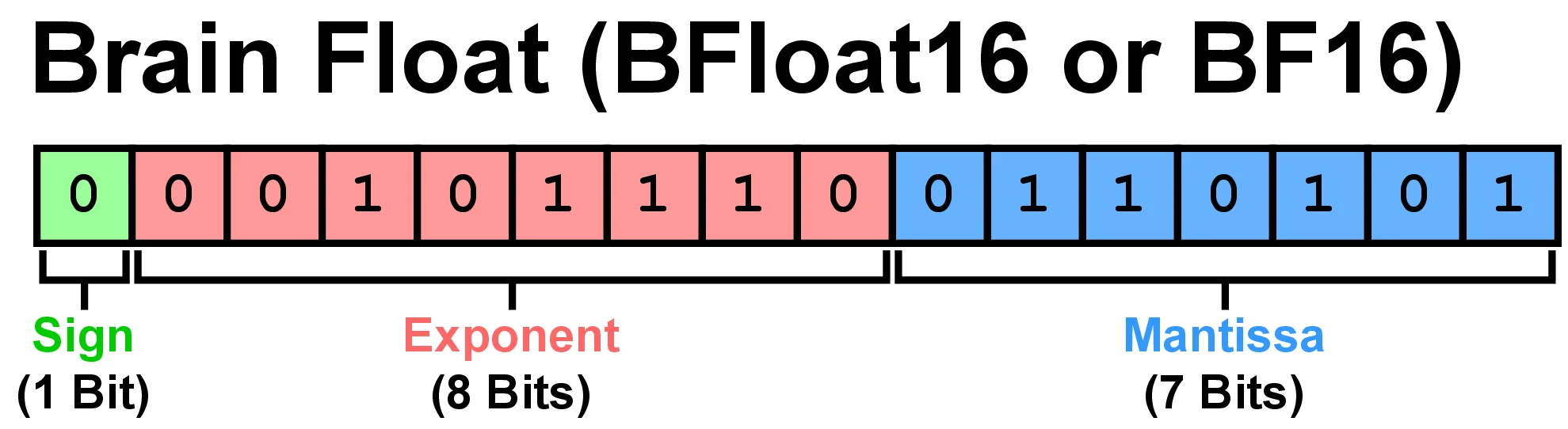
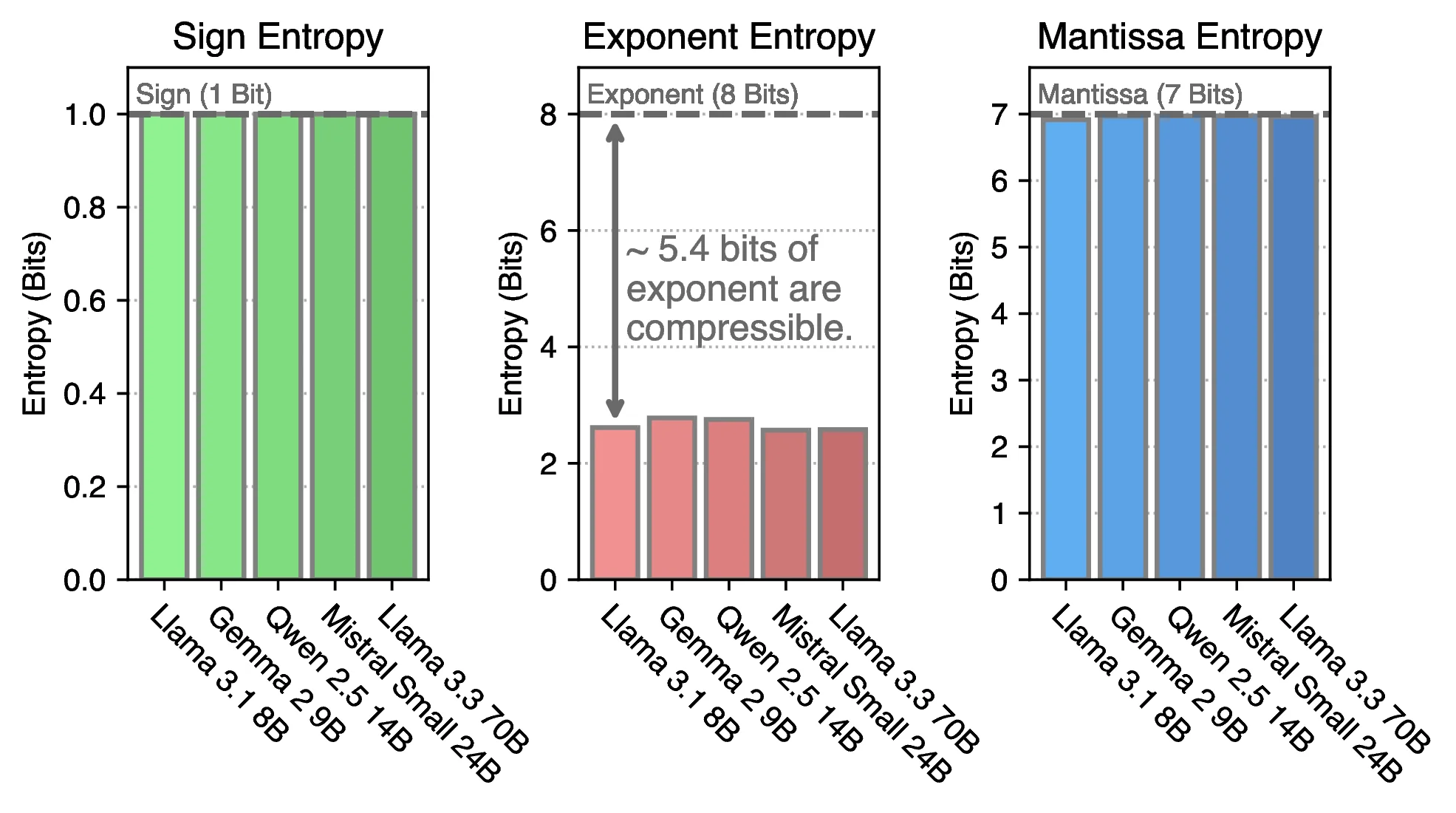 Across LLMs the 8-bit exponent holds only ~2.6 bits of Shannon entropy; sign and mantissa are near-full.
Across LLMs the 8-bit exponent holds only ~2.6 bits of Shannon entropy; sign and mantissa are near-full.2.6 / 8exponent bits used
~40 / 256exponent values seen
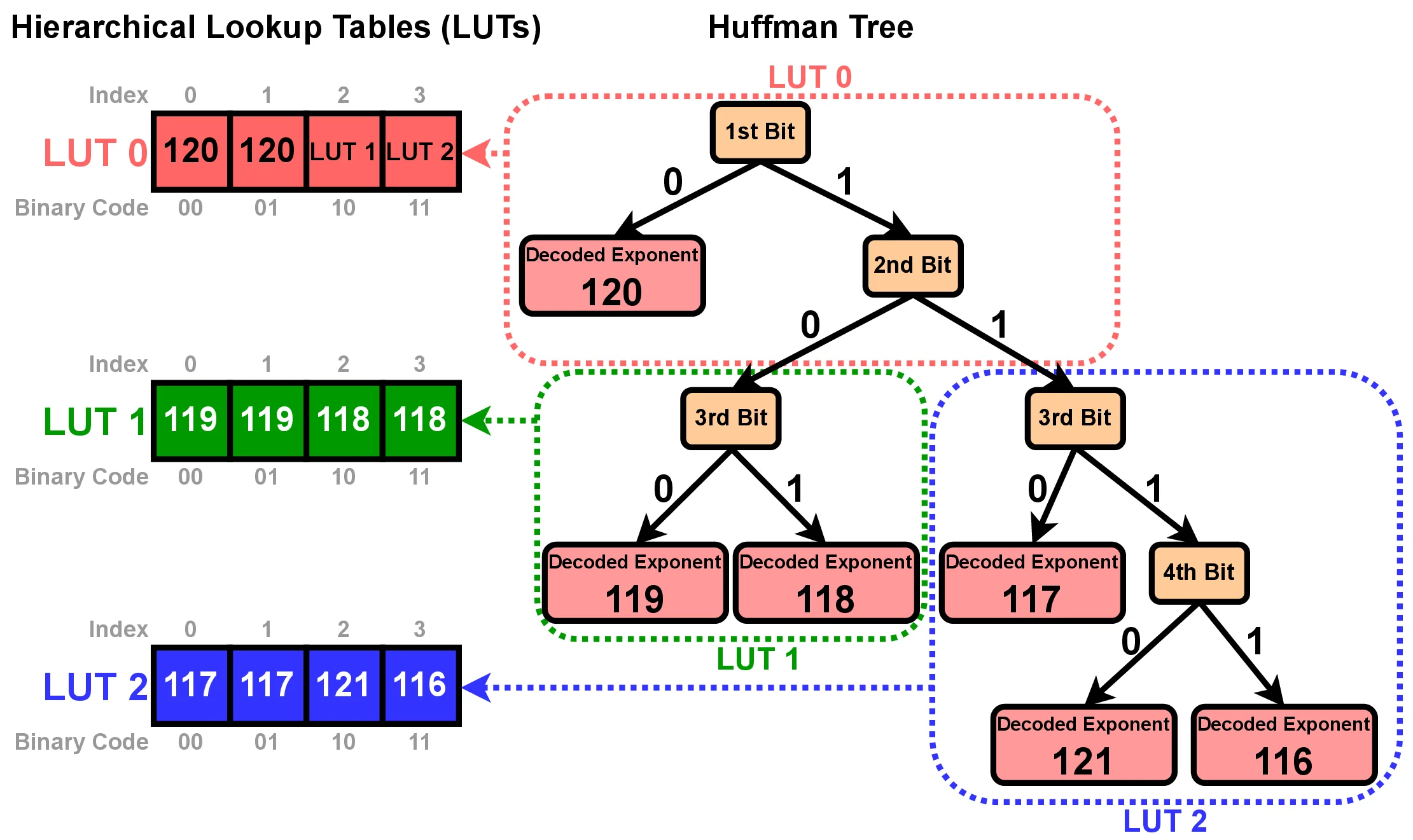
DFloat11: code the exponent, keep the rest
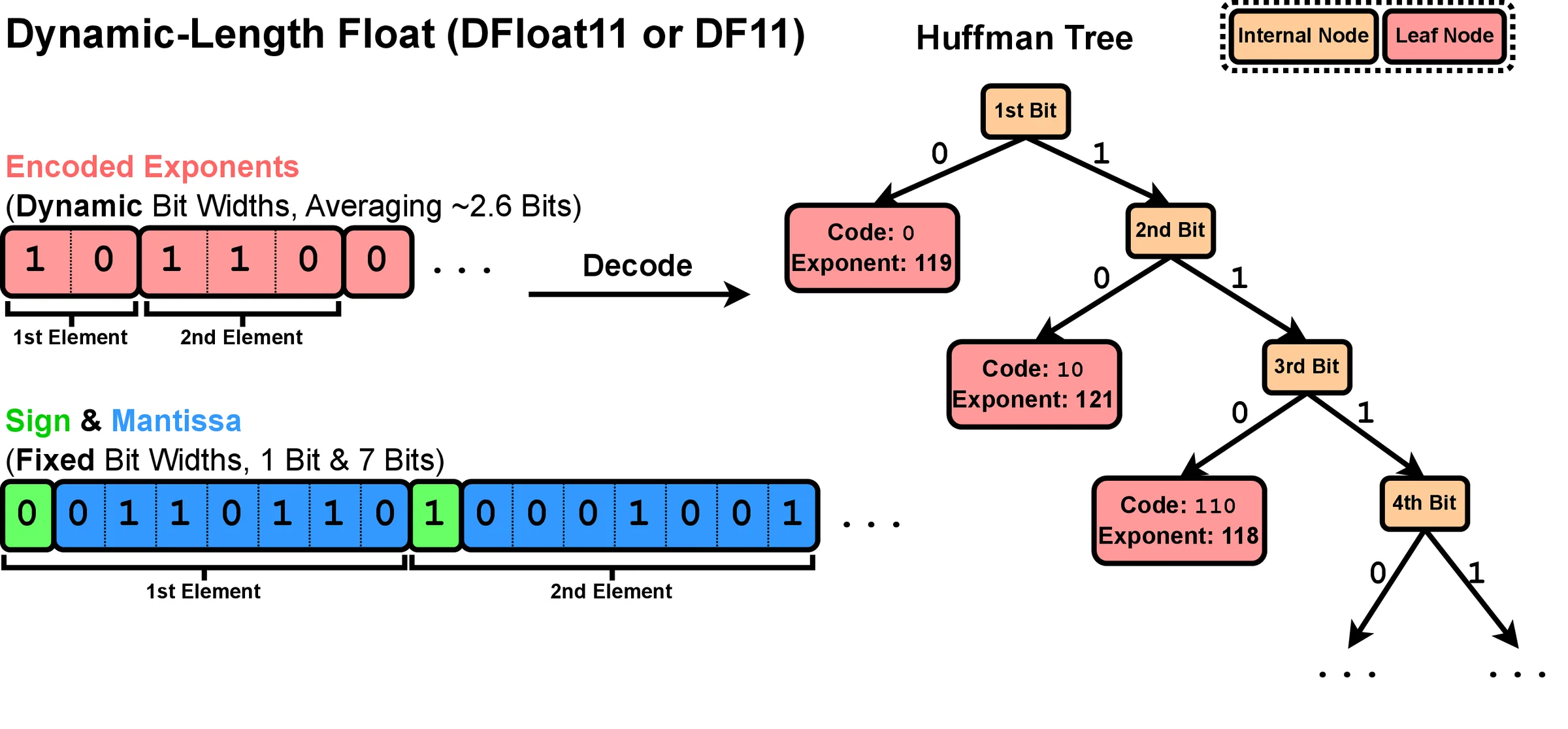 Huffman-code the exponent to dynamic length; the sign and mantissa stay fixed. 16 bits → ~11 bits, decoded with a Huffman tree.
Huffman-code the exponent to dynamic length; the sign and mantissa stay fixed. 16 bits → ~11 bits, decoded with a Huffman tree.(−1)sign×2exp−127×(1.mantissa)
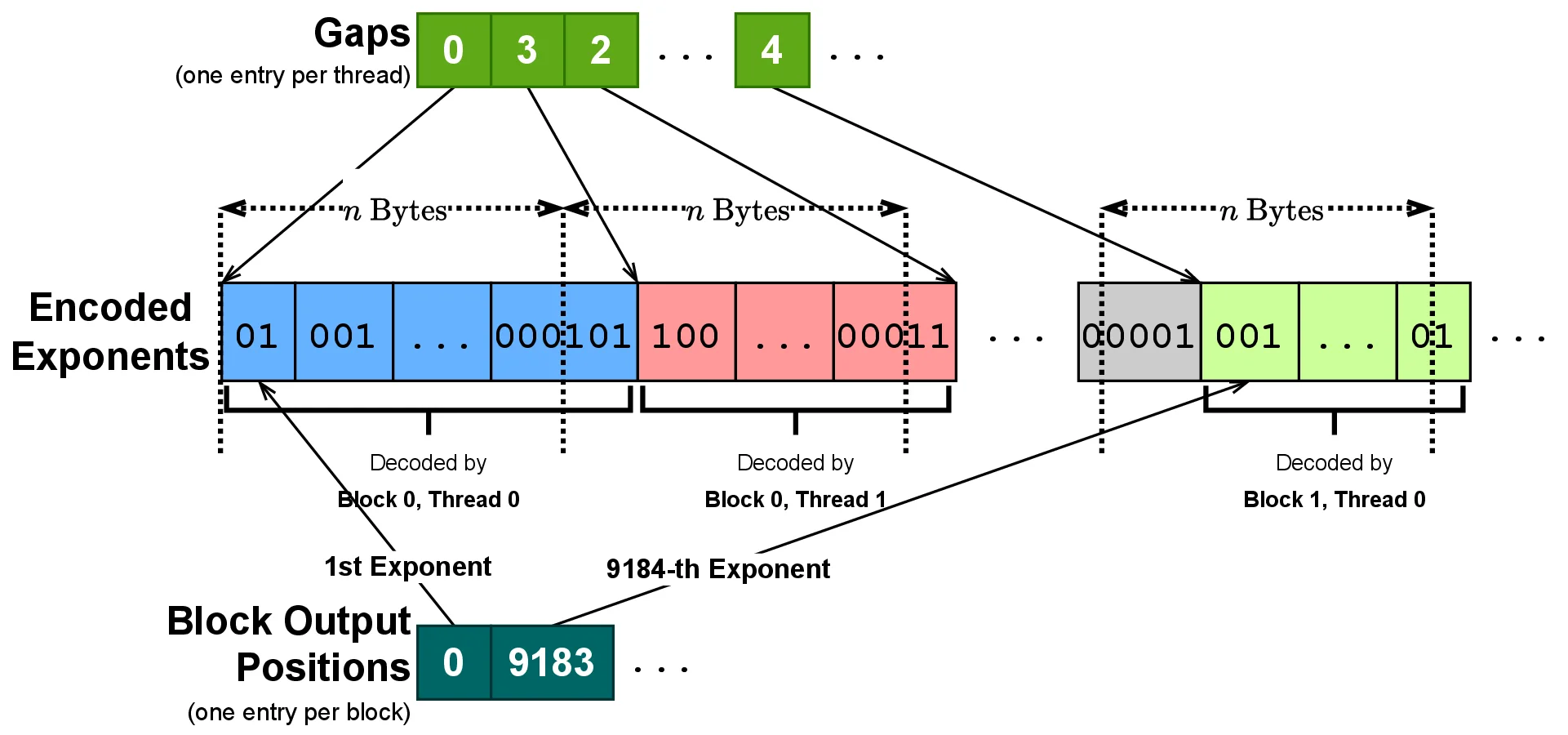
Decoded on the GPU, on the fly
- Compact hierarchical LUTs fit in SRAM for table-based decoding.
- Two-phase kernel with gap & block-output arrays places every thread.
- Block-level batched decompression hides latency.
Kernel internals, math & ablations → Detail
30% smaller, bit-for-bit identical
| Model | BF16 → DF11 | Ratio |
|---|
| Llama 3.1 8B | 16.1 → 10.9 GB | 67.8% |
|---|
| Llama 3.3 70B | 141 → 95.4 GB | 67.6% |
|---|
| Llama 3.1 405B | 812 → 551 GB | 67.9% |
|---|
| Qwen 3 14B | 29.5 → 20.1 GB | 68.2% |
|---|
| FLUX.1 dev | 23.8 → 16.3 GB | 68.6% |
|---|
| SD 3.5 Large | 16.3 → 11.3 GB | 69.5% |
|---|
MMLU, TruthfulQA, WikiText & C4: identical to BF16 (~11-bit average width).
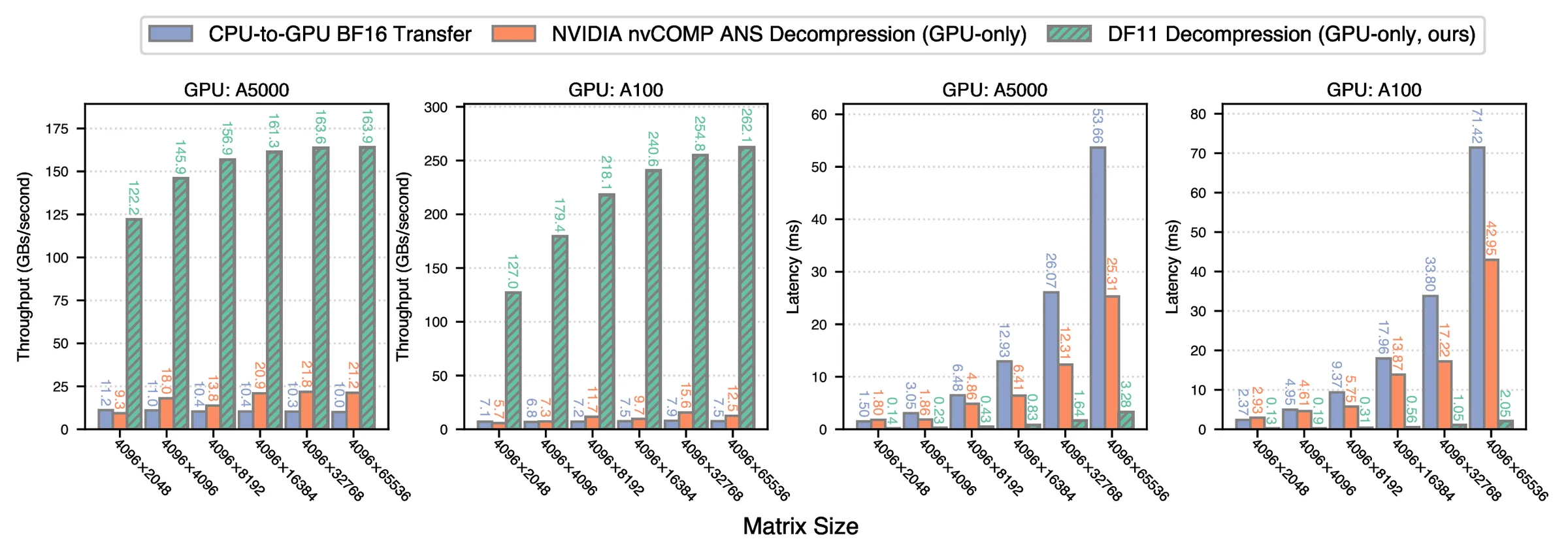
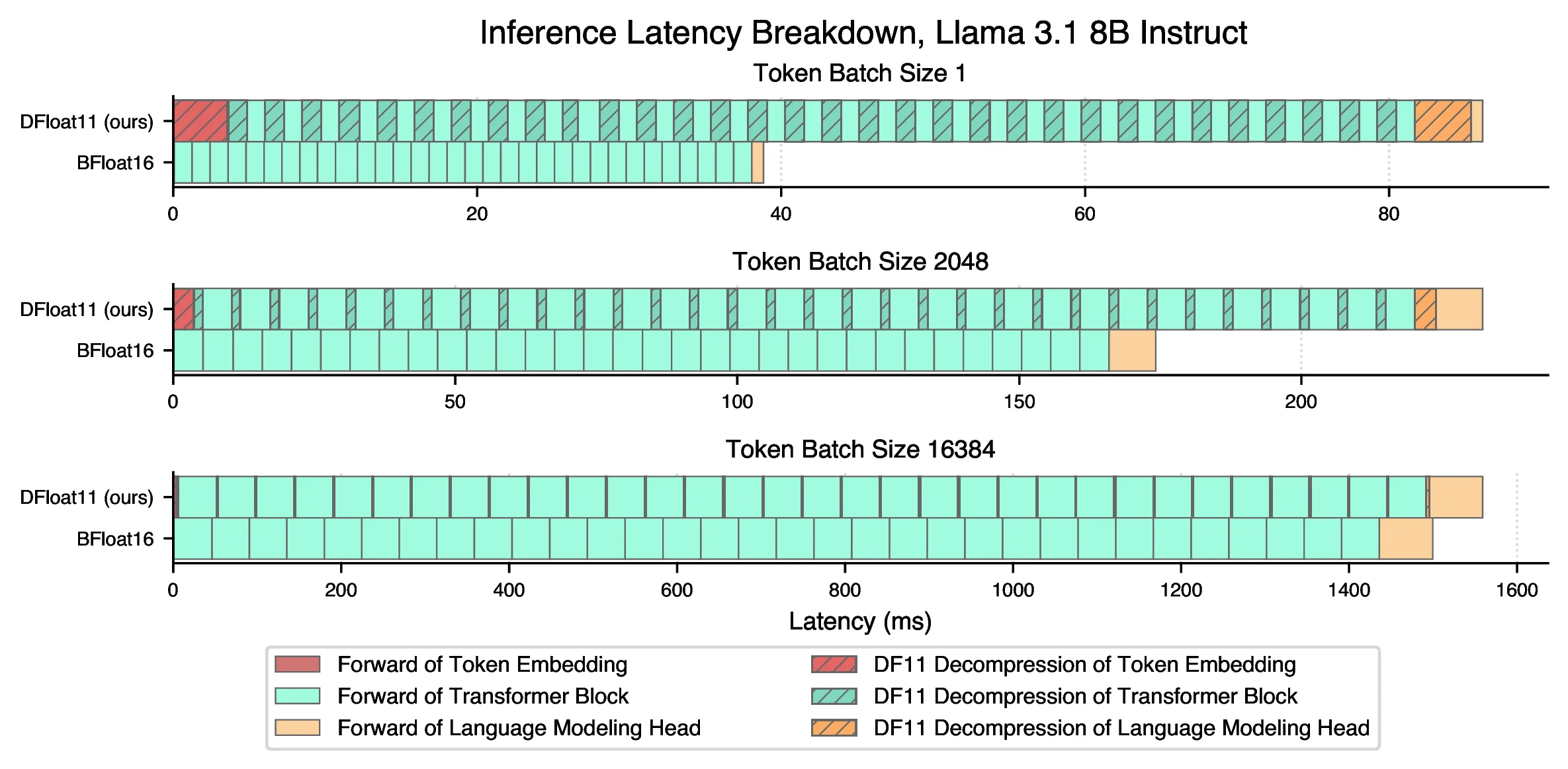
2.3–46.2× faster than CPU offloading
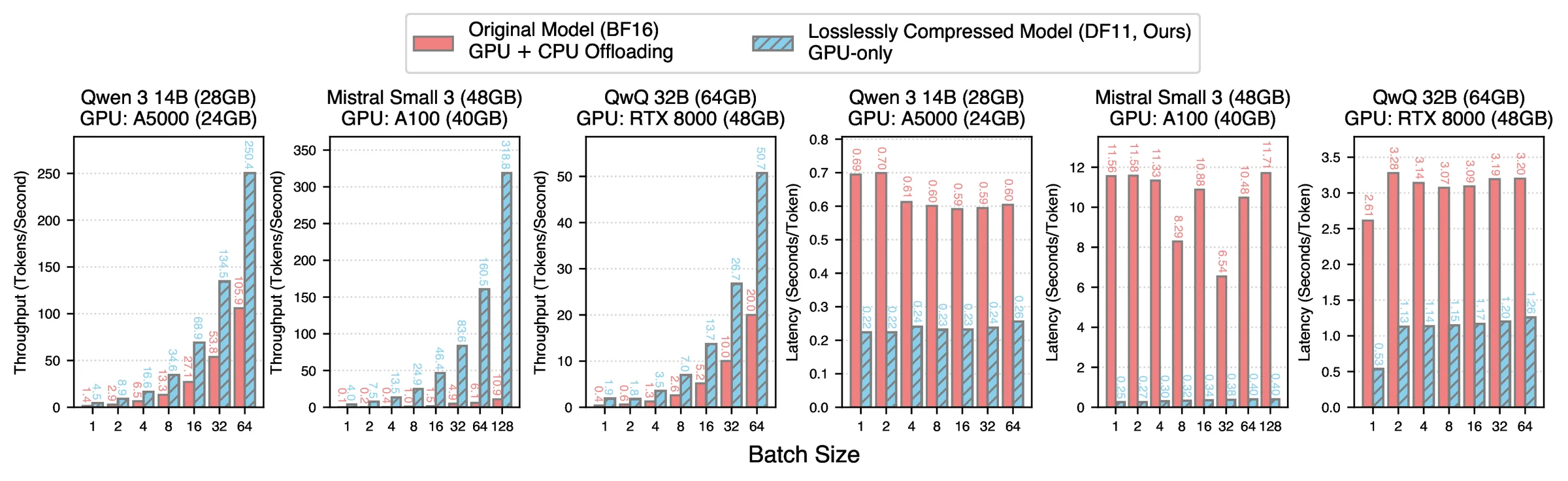 Token throughput (left) and latency (right): DF11 on one GPU vs BF16 with CPU offloading, across batch sizes.
Token throughput (left) and latency (right): DF11 on one GPU vs BF16 with CPU offloading, across batch sizes.46.2×peak vs CPU offload
2.3×worst case, still ahead
5.7–14.9× longer generation
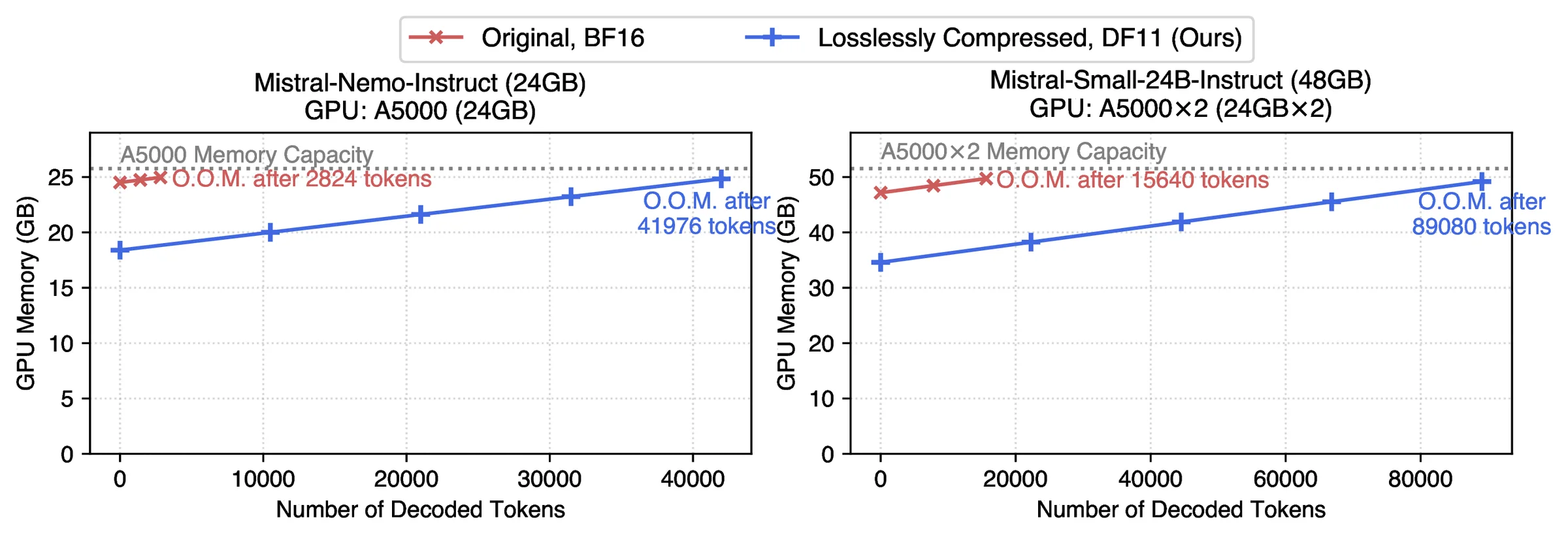 Freed memory feeds the KV cache — DF11 decodes 5.7–14.9× more tokens before running out of memory.
Freed memory feeds the KV cache — DF11 decodes 5.7–14.9× more tokens before running out of memory.14.9×more tokens before OOM
28%less memory (diffusion)
Takeaways
- 30% smaller, for free
- Bit-for-bit lossless
- 405B on one 8×80GB node
- LLMs & diffusion models