Test-Time Scaling & Ranking
- The primitive object is a response tensor.
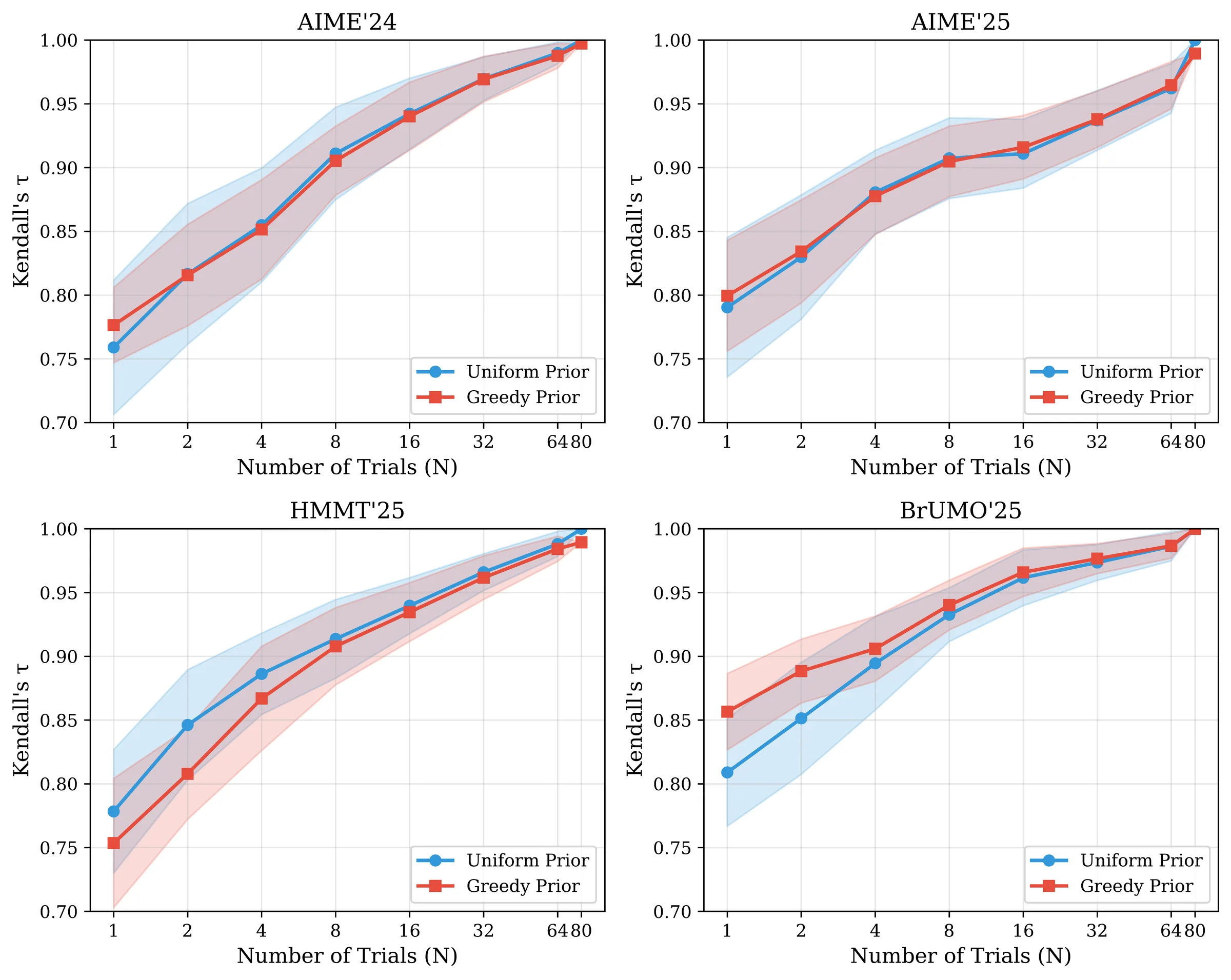
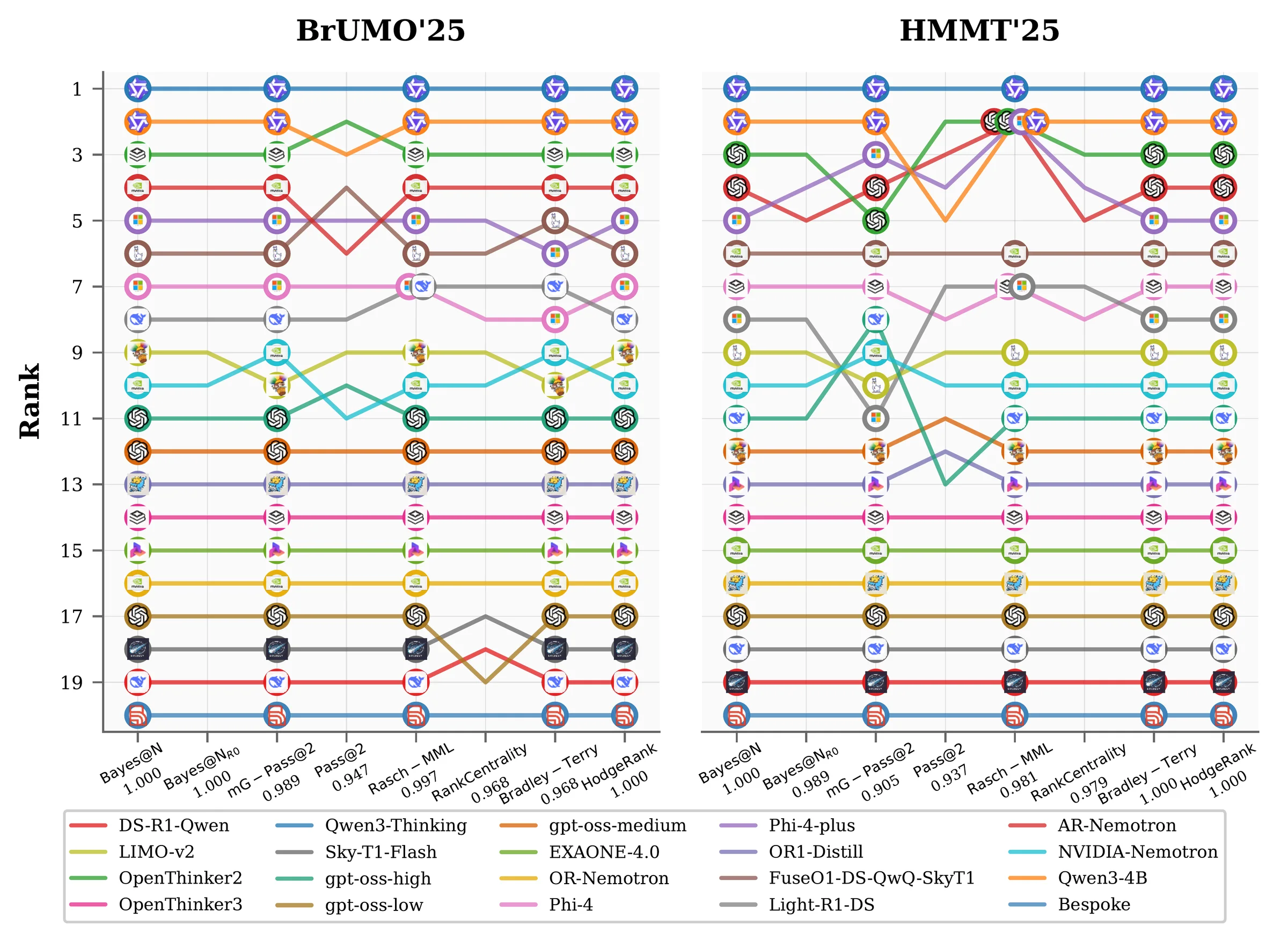
- Each model-question pair can be sampled repeatedly, so rankings change as the trial budget grows.
- Methods that look similar at full budget can behave very differently when only one or two trials are available.
- Collect repeated trials per question
- Apply one ranking family to the tensor
- Use as the gold standard
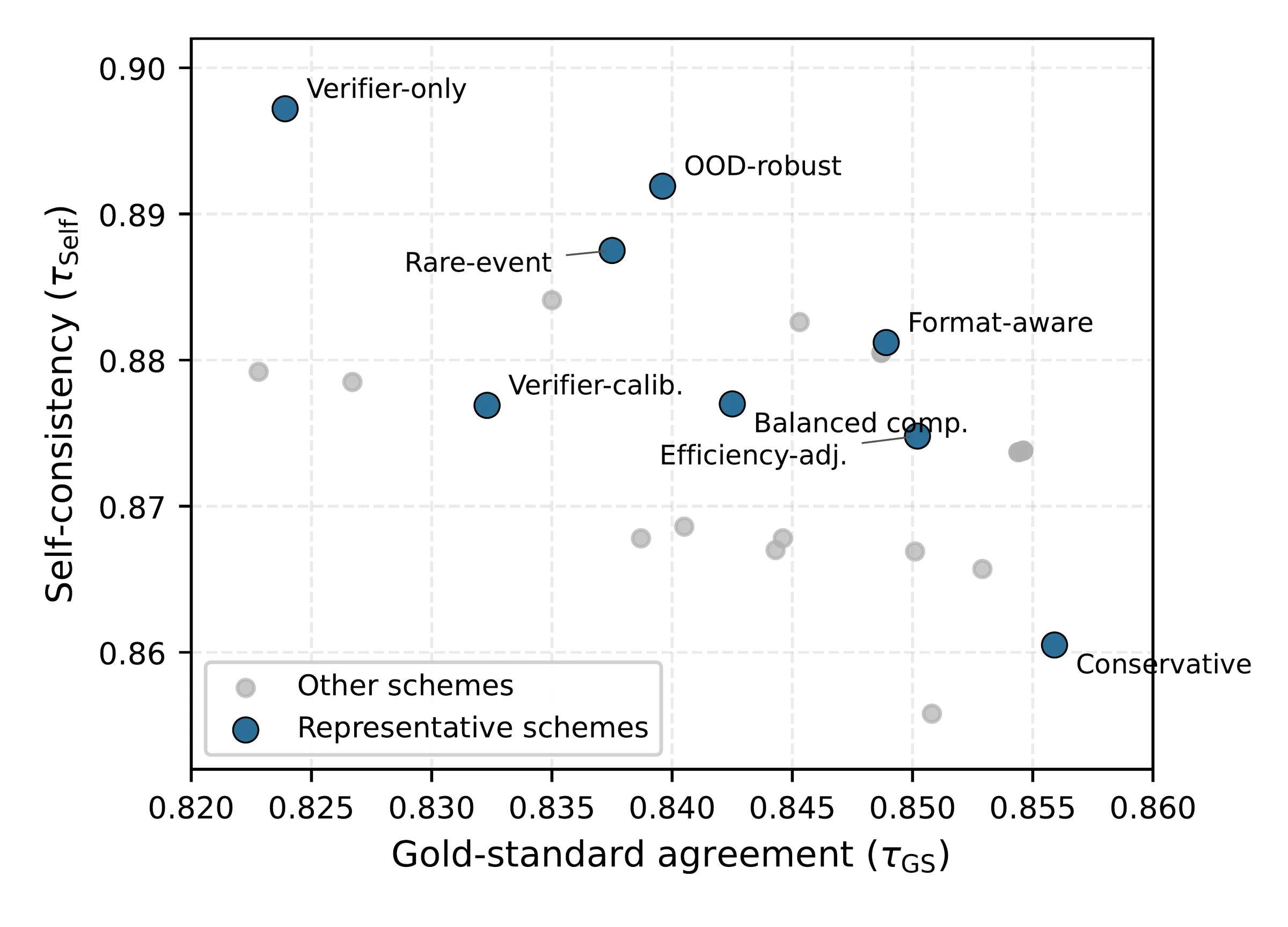
- Measure agreement and convergence as N grows
- Prefer rules that stay stable at low budget
Distinction: high-budget consensus tells us what methods eventually agree on; low-budget stability tells us what you can trust in practice.
from scorio import rank
rank.avg(R)
rank.bayes(R, R0=None, quantile=None)
rank.pass_at_k(R, k=3)
rank.bradley_terry(R)
rank.pagerank(R)