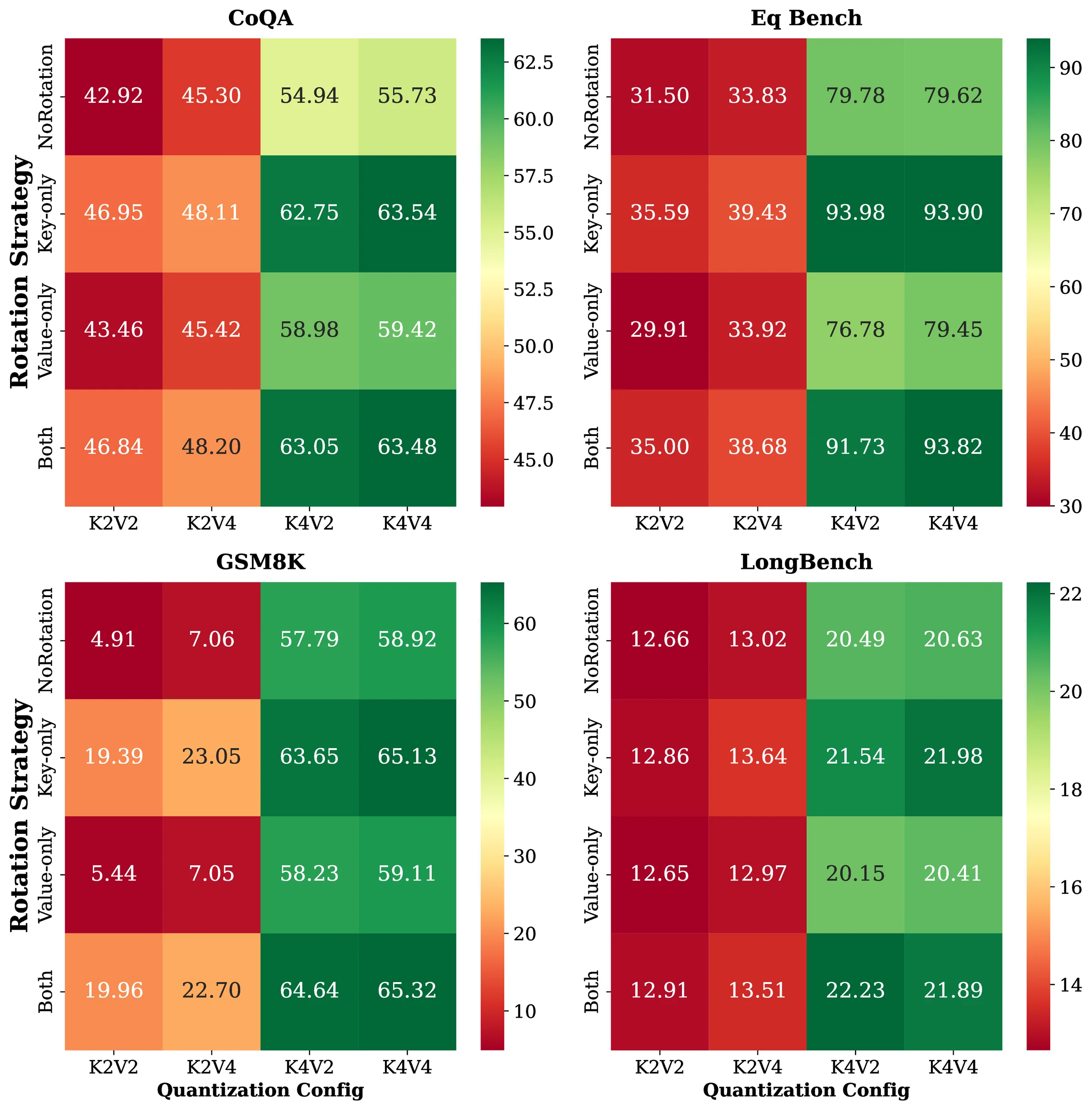
A common practice is to use the same quantization bit width for key and value caches.
98.3%avg. K4V4 accuracy retained by K4V2 with HQQ
25%KV-cache memory reduction versus K4V4
+48 ppGSM8K gain when the extra bit goes to keys at ultra-low precision
From Norm Gap to Bit Rule
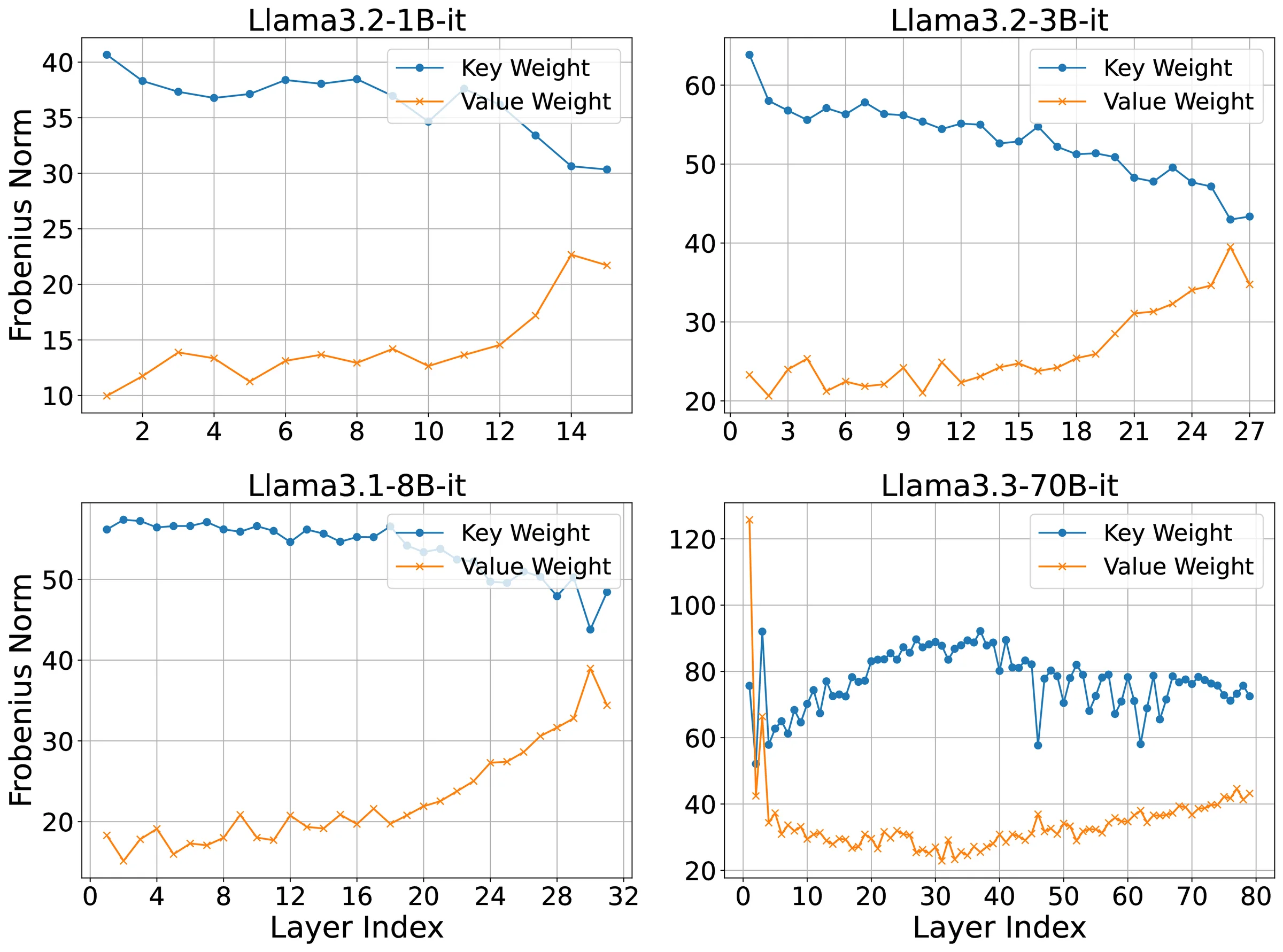
Measure∥WK∥F>∥WV∥F
Bound∥A−A∥F∝2−b∥A∥F
AllocatebK>bV
Theorem 1: Key-Value Norm Disparity
Key projection weights carry larger energy than value weights.
E[∥WK∥F]>E[∥WV∥F].
Consequence A one-time weight diagnostic predicts which cache is more fragile.
Theorem 2: Key-Prioritized Quantization
With a fixed bit budget, the larger-norm cache should receive extra precision.
E[∥K∥F2]>E[∥V∥F2] ⇒Acc(bK,bV)>Acc(bV,bK).
Consequence For the same memory budget, K4V2 beats the swapped split.
In practice: Keep keys sharp. Compress values first.
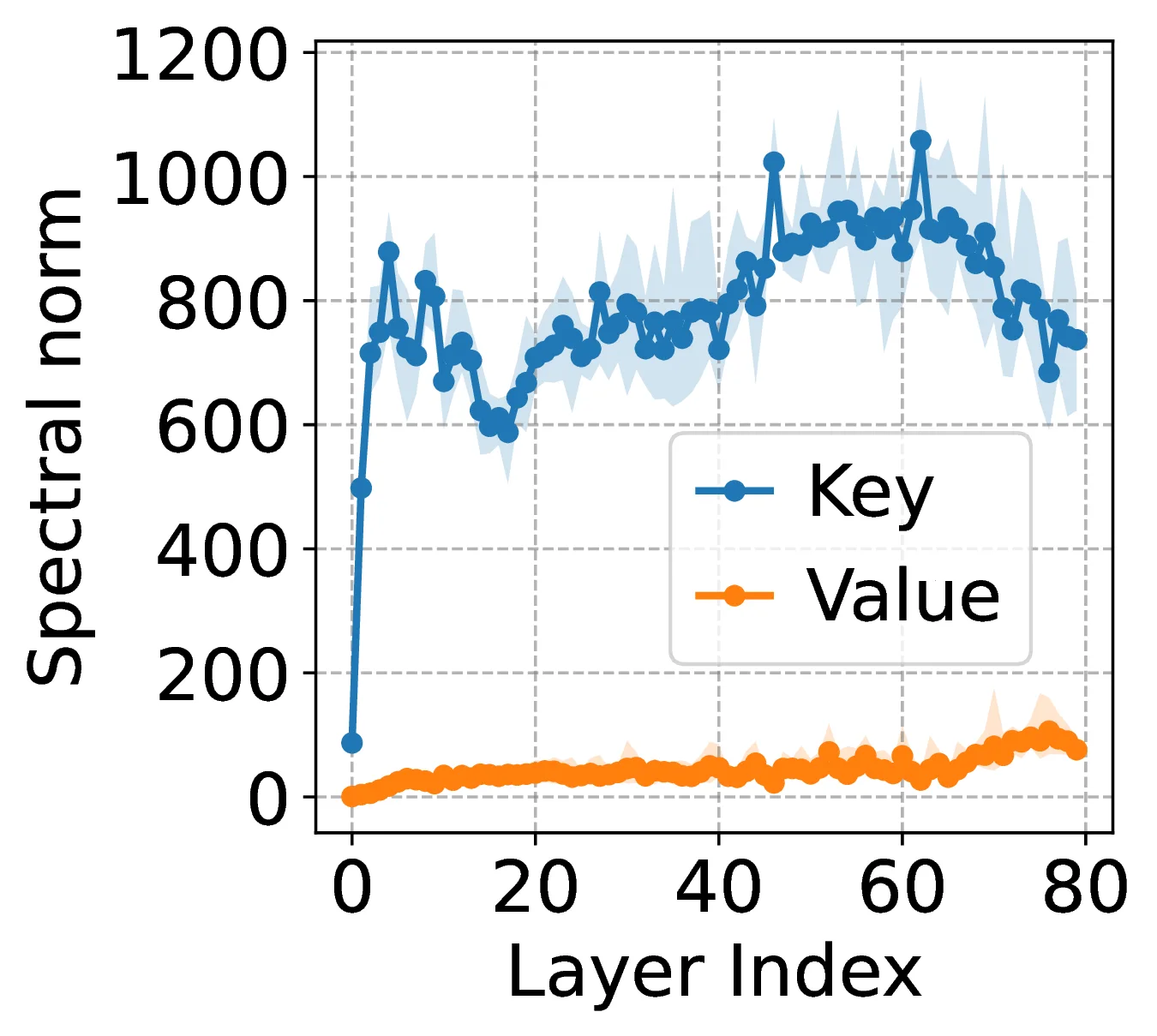
Norm Dynamics of KV Weights
Across models, ∥WK∥F exceeds ∥WV∥F in almost every layer.
The asymmetry follows the attention path: keys shape lookup geometry; values carry retrieved content.
Equal bit-widths under-protect the higher-energy signal.
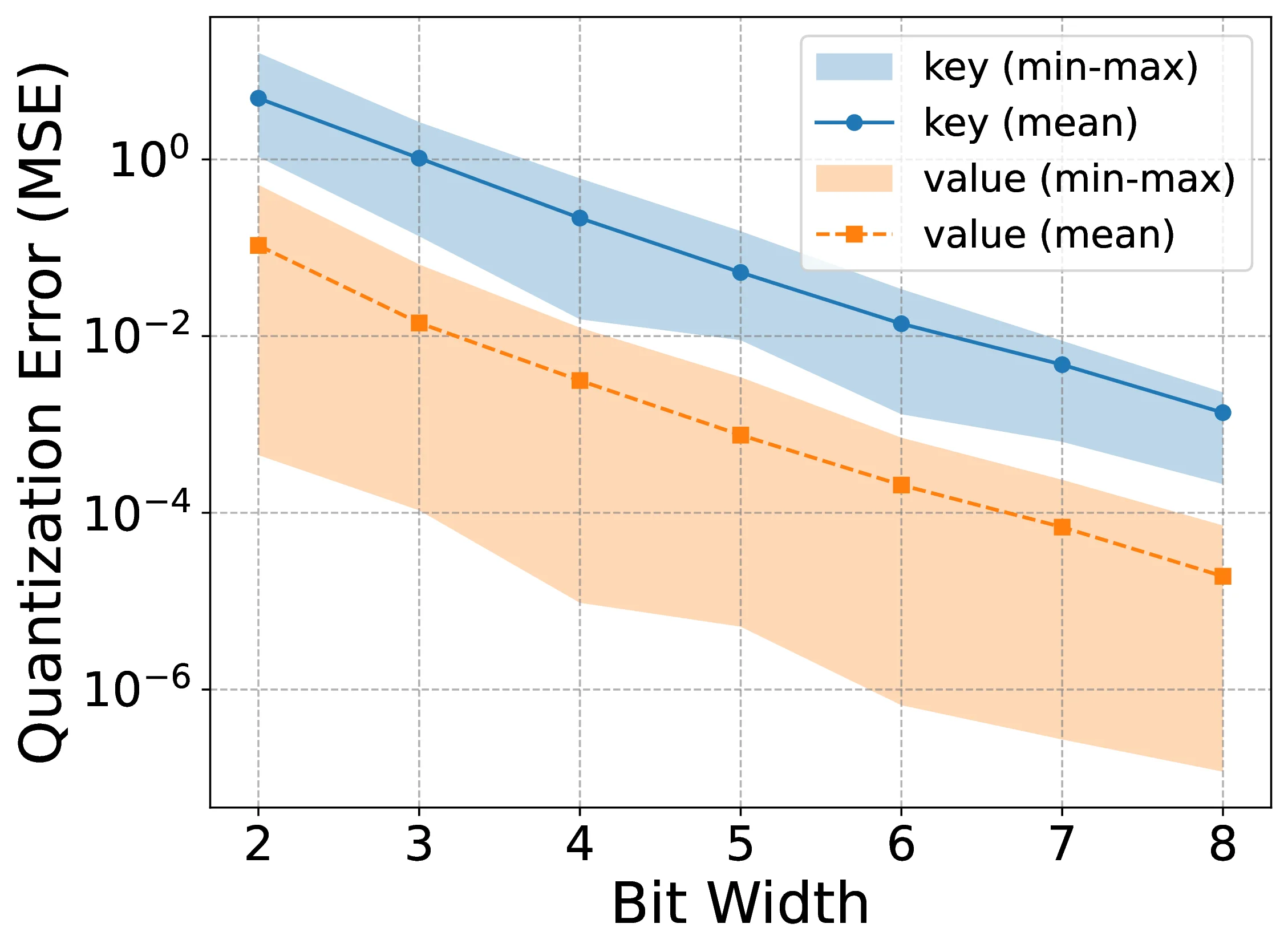
Quantization Error (MSE)
Matched bitsMSE(Kb)>MSE(Vb)
Error rulespend precision on keys first
MSE is the Frobenius reconstruction error per cache entry: ∥M−M∥F2/nnz(M). On Llama 3.3-70B/C4, key-cache error stays above value-cache error from 2 to 8 bits, so equal bit-widths leave the dominant distortion in K.
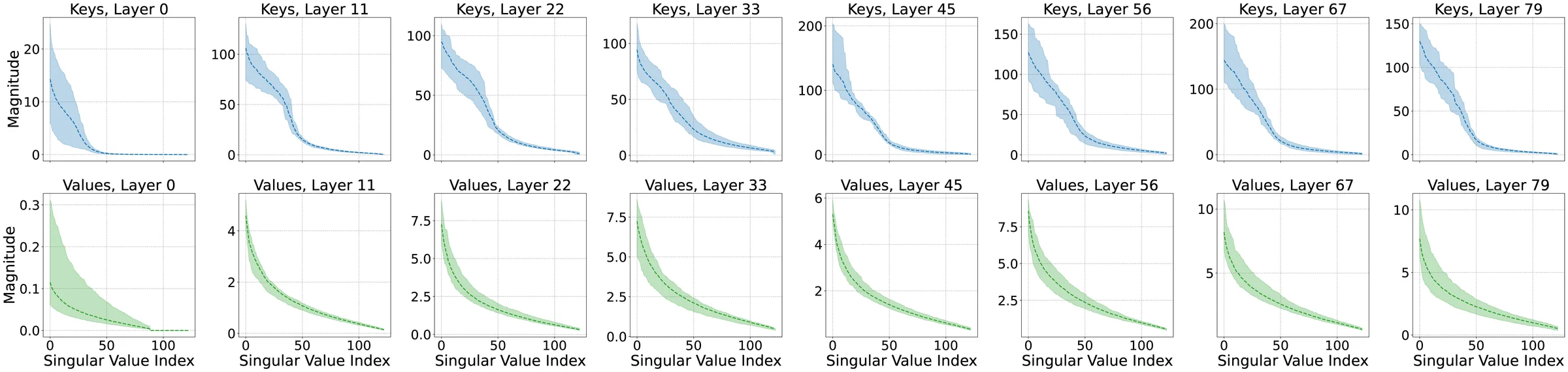
Geometry of Key Value Caches: Singular Value Spectra
Keys hold broader high-magnitude spectra. The gap persists across layers in Llama 3.3-70B on C4.
Practical reading: protect the addressing channel first; shrink the payload channel after.
Orthogonal Synergy: Fix Key Distortion First
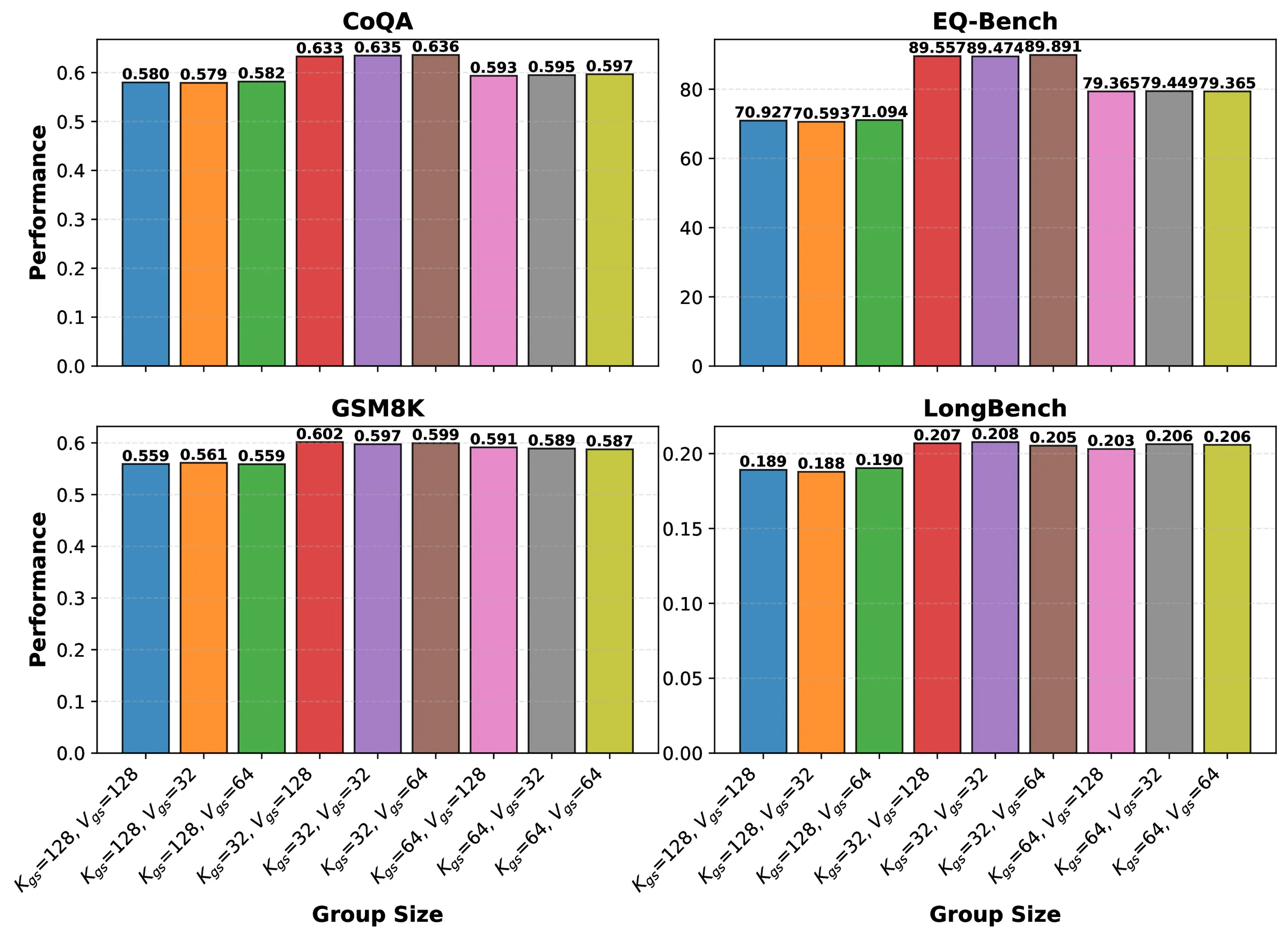
K4V2+key-only rotation closely tracks the K4V4 baseline; rotating both adds little beyond keys.With K4V2, gsK=32 is best overall; gsV=64 or 128 preserves accuracy with less overhead.