3D grounding fails on the language side, not the eyes
VLMs name anatomy correctly yet misplace it: small decoding shifts flip directional terms (superior ↔ inferior), an error that compounds under chain-of-thought reasoning.
A 3D volume is an ordered stack of slices, so video-native VLMs read it directly — but no benchmark isolates where grounding breaks.
We vary five factors and fix one failure mode at decode time, free.
ModalityCT · MRI
Sliceaxial / coronal / sagittal
CoordinatesRAS storage vs. viewing
Visual promptmask · box · point
Termsanatomical vs. colloquial
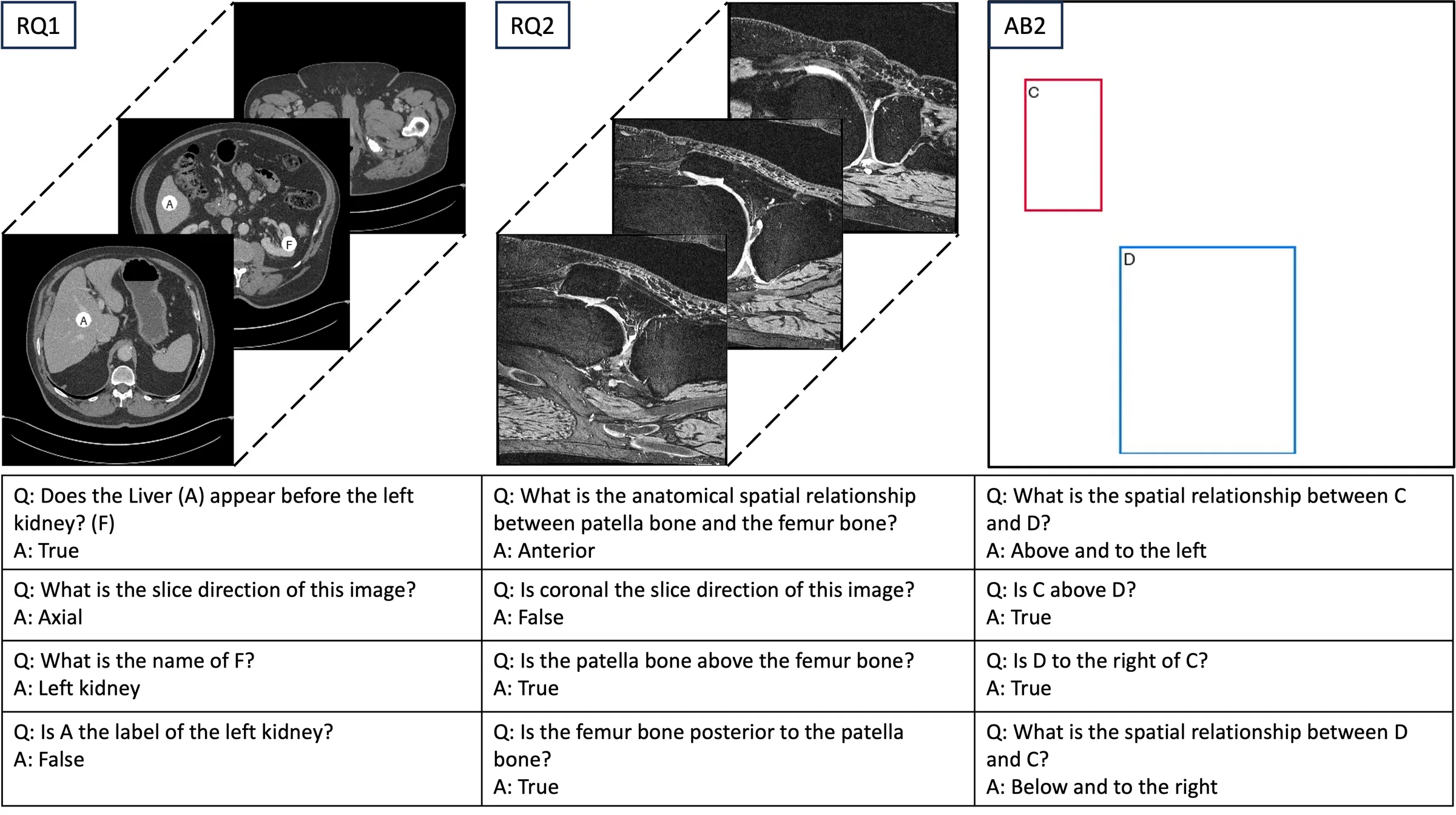
MIS-Ground probes grounding under a controlled factorial design
Each 2D/3D input spawns many questions: cross-slice relationships (RQ1), anatomical vs. colloquial terms (RQ2), and abstract reasoning on bare prompts (AB2).
1,1603D volumes · 2,320 2D slices
33,864spatial-grounding questions
77anatomical components (67 CT, 10 MRI)
CT from TotalSegmentator (1,228 torso scans, ~84% of the set, avg 2,757 Q/scan); MRI from OAI knee (209 DESS scans, avg 683 Q/scan). First benchmark to jointly vary modality, slice, coordinates, prompt, and terminology.
Semantic Sampling stabilizes decoding for free
At each step, keep the standard top-M/top-p candidates, then re-score every content token by the probability mass of its cosine-kNN neighborhood in embedding space — coherent regions win over locally lucky tokens.
Neighborhoods are built over content tokens only; special, control, and modality markers are excluded so they cannot become embedding hubs.
If any candidate is a non-content token, the step defers to default decoding.
Pick argmax for reproducibility, or softmax-sample for chain-of-thought.
Training-freeModel-agnosticNo extra forward passO(|It|·K) lookups/token
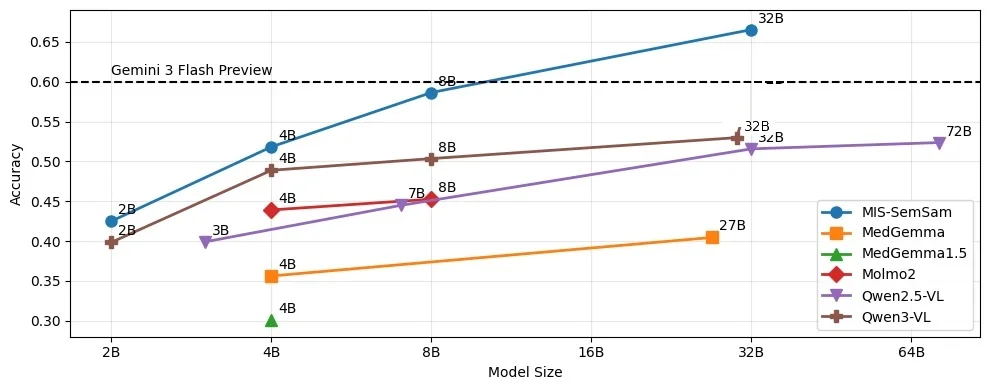
Semantic Sampling lifts Qwen3-VL-32B to 66.5%
Accuracy climbs with model size; MIS-SemSam (Qwen3-VL-32B + semantic sampling) tops every open-weights family and the Gemini 3 Flash reference.
53.4%Qwen3-VL-32B, default decoding
66.5%+ MIS-SemSam (+13.06%)
Same model, prompts, images, and questions — only the token-selection rule changes, so the gain is a paired comparison. M3D (15.9%) and Med3DVLM (0.0%, malformed output) trailed on resizing and rigid formatting, not on spatial capacity.
What MIS-Ground reveals about 3D grounding
RQ1 3D nearly matches 2D
Slice direction predicted at 77.6%; cross-slice relationships 68.0% vs. in-plane 71.7%. Overall 3D 56.9% tracks 2D 58.8%.
RQ2 View flips the preferred terms
Standard viewing favors anatomical terms (69.4% vs. 57.8%); RAS storage inverts it (colloquial 59.9% vs. anatomical 50.2%) as priors fight the non-standard view.
RQ3 Prompts help only when text is weak
From a 57.6% standard-view baseline, prompts add little (+2–3%). They degrade a strong 75.3% anatomical baseline (−13.3% points) yet rescue a weak 45.1% colloquial one (+8.2%).
AB1 Heavy reliance on anatomy priors
Text-only (no image) anatomical relationships hold at 69.3% vs. 74.0% with the image; colloquial text-only collapses to 40.4%.
AB2 Capable abstract reasoning
Prompts on a blank background, no scan: points 64.2%, boxes 60.4% — spatial reasoning survives without the medical image.
Setup Robust, reproducible eval
Reasoning decode, max 8,912 new tokens, T=0.5; accuracy reported with Bayesian credible intervals over limited trials.
Takeaways
3D anatomical grounding is measurable, not random — MIS-Ground isolates where VLMs break instead of reporting one aggregate failure.
The bottleneck is language-side brittleness — conflicts between anatomy priors and the on-screen view drive most errors.
Semantic Sampling buys accuracy at no cost — +13.06% on Qwen3-VL-32B with no training and no extra forward pass.
Fix decoding, not the model: aggregating semantic-neighborhood mass at the final token choice recovers grounding that default sampling throws away.
Acknowledgment: This research was supported in part by NSF awards 2117439 and 2320952. Affiliations: Case Western Reserve University and Cleveland Clinic, Cleveland, OH, USA.
Email verification challenge
A reCAPTCHA-style challenge that reveals the email address.