Medical Image Spatial Grounding with Semantic Sampling
- 1Case Western Reserve University, Cleveland, OH, USA
- 2Cleveland Clinic, Cleveland, OH, USA
†Equal contribution
TL;DR: Vision-language models are better at 3D medical spatial grounding than the literature suggests. The failures are mostly on the language side, not in the eyes. We built MIS-Ground, a controlled benchmark of 33,864 questions that isolates which factor (modality, view, coordinate convention, visual prompt, terminology) breaks a model's grounding, and MIS-SemSam, a training-free decode-time rule that re-scores each next token by its semantic neighborhood. On MIS-Ground, MIS-SemSam lifts Qwen3-VL-32B from 53.4% to 66.5% (+13.06%), the best open-weights result and above the Gemini 3 Flash reference, with no training and no extra forward pass.
The failures are in the words, not the pixels
Most reports on medical VLMs end in the same place: the model handles easy questions, falls apart on spatial ones, often close to random, and the paper concludes it cannot really see. We started from a narrower guess. In our runs the recognition was usually there. The model would localize the femur correctly and then, on one unlucky decode, call it inferior to the tibia when it meant superior, or slide into a neighboring anatomical term that was almost right. Under chain-of-thought this got worse, because a single off token sets the direction for everything that follows.
If that is the real bottleneck, the failure is on the language side, not in the eyes, and two things follow. You need a benchmark that can tell you which condition triggers the slip. And you might recover a lot of it without retraining anything, just by changing how the last token gets picked. MIS-Ground is the first; MIS-SemSam is the second.
A benchmark that says where grounding breaks
Prior medical-grounding studies report one aggregate failure number. MIS-Ground is, to our knowledge, the first to probe 3D anatomical grounding under a controlled factorial design, where every question is a point in a grid of five factors, so a low score points at a factor instead of a fog:
- Modality: knee MRI (from the Osteoarthritis Initiative) and torso CT (from TotalSegmentator).
- Slice direction: axial, coronal, or sagittal, rendered by multi-planar reconstruction.
- Coordinate convention: RAS storage (origin at the RAS-most voxel) versus the standard viewing orientation a radiologist would use.
- Visual prompt: mask, bounding box, or point, uniquely colored and labeled A–F.
- Terminology: anatomical (superior) versus colloquial (above) direction terms.
Each question is then posed three ways (open-ended, closed-True, closed-inverted-False), and two ablations strip the inputs further: text only, or visual prompts on a blank background with no scan.
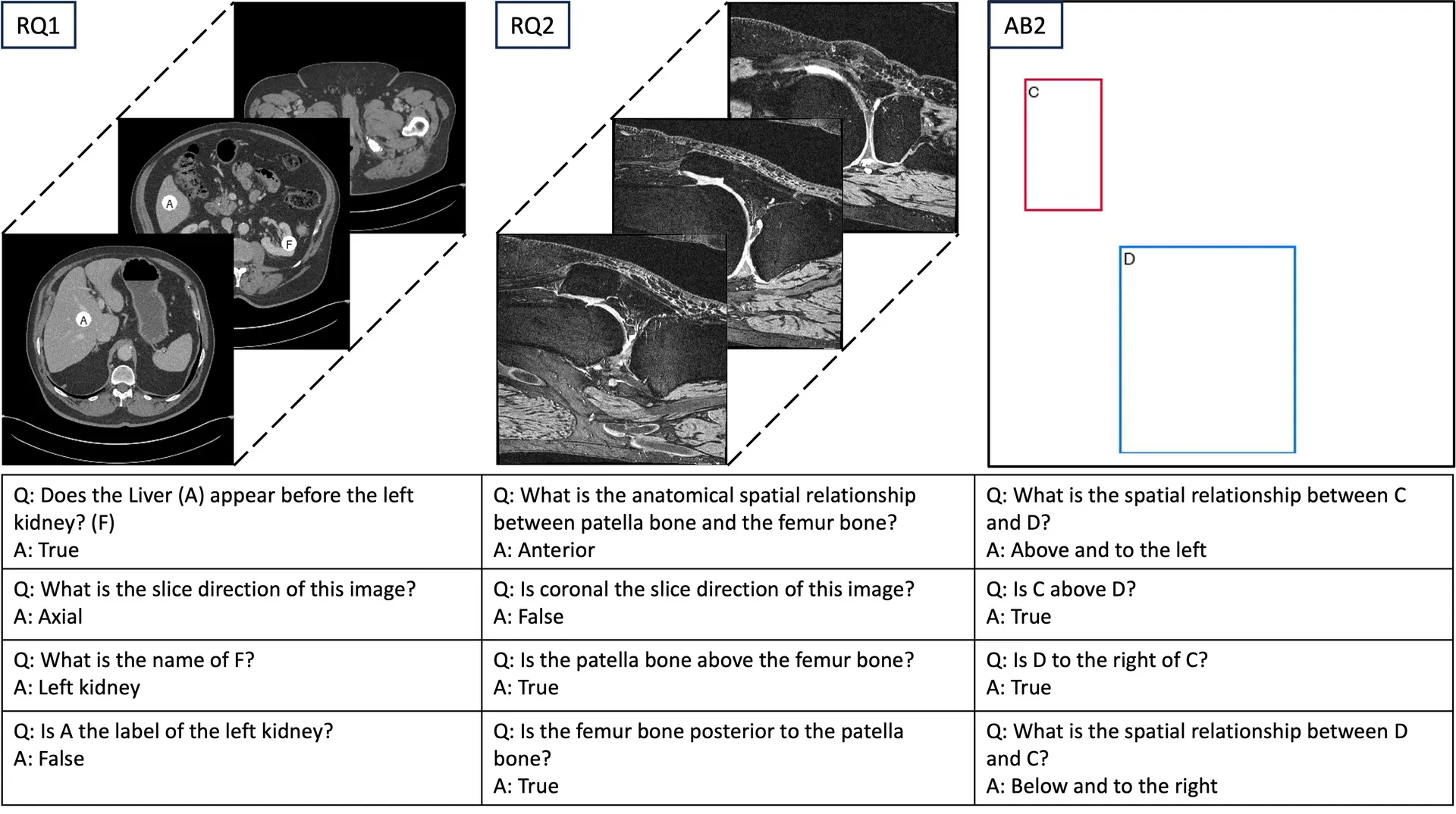
The sweep is large: 1,160 3D volumes become 2,320 2D slices and 33,864 questions across 77 anatomical components (67 in CT, 10 in MRI). We sampled CT harder to balance components, so it is about 84% of the set and the aggregate is CT-weighted; read the scores at the benchmark level, not as a clinical-readiness claim. Because each model runs under a fixed reasoning-decode budget over a handful of trials, we report accuracy with Bayesian credible intervals rather than raw point estimates, using the Bayes@N protocol from our earlier work.
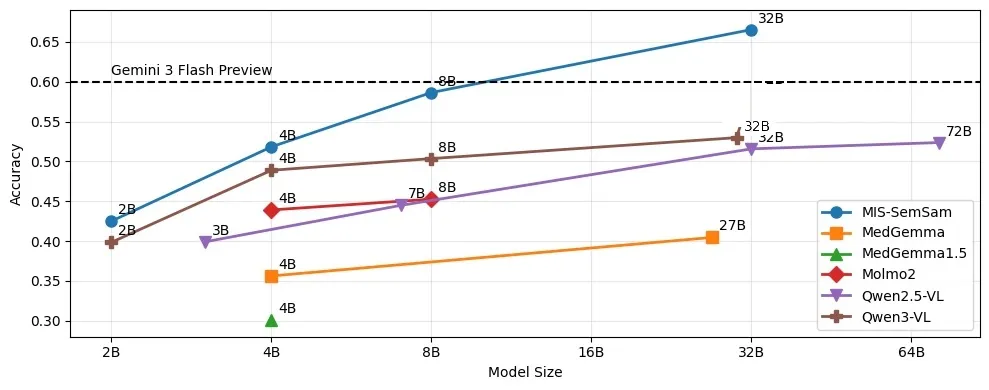
One number to remember: 66.5%, above Gemini 3 Flash
Accuracy tracks model size, but version matters more than raw scale: Qwen3-VL-32B beats the larger Qwen2.5-VL-72B. On the best open-weights backbone, Qwen3-VL-32B, adding MIS-SemSam moves overall accuracy from 53.4% to 66.5%. That crosses the roughly 60% Gemini 3 Flash Preview line. A video-native open model, trained on natural scenes and never on our scans, edges past a strong closed reference on 3D medical grounding.
The gain is a paired comparison by construction. The model, prompts, images, questions, and inference settings are all held fixed; only the final token-selection rule changes. (Two dedicated 3D-medical VLMs, M3D and Med3DVLM, scored 15.9% and 0.0%, but that reflects aggressive input resizing and malformed output formatting, not an absence of spatial capacity, so it is not a verdict on 3D medical VLMs.)
How MIS-SemSam works: trust the neighborhood, not the lucky token
The idea is one sentence. When the model is unsure among several near-synonyms of the same concept, which is exactly the situation with directional and anatomical terms, don't pick the next token by its own probability alone. Prefer tokens supported by probability mass across their local semantic neighborhood in embedding space. If a candidate's neighbors also carry mass, the model really means that region of the vocabulary, so commit to it; a locally lucky but semantically isolated token gets damped.
Two details make it work for VLMs. Neighborhoods are built over content tokens only, so special, control, and modality markers (image delimiters, role tokens) are excluded, because otherwise they become embedding-space hubs that contaminate the nearest-neighbor structure. And it is a drop-in: it replaces only the final "pick the next token" step and leaves the vision encoder, the prompt, and the truncation filter untouched, with no extra forward pass.
Concretely, precompute once per embedding space the cosine k-nearest-neighbors of every content token, storing neighbor ids and their cosine similarities . At decode step , take the temperature-scaled next-token probabilities , apply the usual top- / top- filter to get a candidate set , and, when every candidate is a content token, re-score each candidate by the mass of its neighborhood:
Negative cosines are clamped to zero so dissimilar tokens cannot cancel real mass. Then take for reproducibility, or softmax-sample the scores when you want chain-of-thought exploration. If any candidate is a non-content token, the step defers to the model's default decoding. The cost is table lookups per token.
The rescoring step is a few lines on top of any next-token distribution:
import numpy as np
# Precomputed once, over content tokens only:
# S_tid[c] -> ids of token c's cosine-kNN neighbors (c included)
# S_val[c] -> the matching cosine similarities
# probs -> temperature-scaled next-token distribution over the vocabulary
# candidates -> the top-M / top-p survivors this step (all content tokens)
def semantic_scores(candidates, probs, S_tid, S_val):
scores = {}
for c in candidates:
w = np.clip(S_val[c], 0.0, None) # drop negative cosines
scores[c] = float(np.dot(w, probs[S_tid[c]]))
return scores
scores = semantic_scores(candidates, probs, S_tid, S_val)
next_token = max(scores, key=scores.get) # argmax; softmax-sample for CoTThe full integration for the Qwen3-VL family is in the released code.
What breaks, and what holds up
The clearest tell is what happens when you flip the view. In a standard viewing orientation the model leans on its anatomical priors and does better with anatomical terms (69.4%) than colloquial ones (57.8%). Put the same scan into RAS storage orientation, where the stored coordinate frame no longer matches how a radiologist would look at it, and the preference inverts: colloquial terms win (59.85%) over anatomical ones (50.2%). The model's memorized body-knowledge prior is now fighting the pixels, and view-relative wording, which only describes what is on screen, takes over. That reversal is the single clearest signature of language-side brittleness in the study.
The rest lines up with that reading. Video VLMs really do read the third dimension: they name the slice direction 77.6% of the time and answer cross-slice questions (68.0%) nearly as well as in-plane ones (71.7%), so 3D overall (56.9%) tracks 2D (58.8%). Visual prompts help only when there is no strong prior to lean on; from a weak 45.1% colloquial baseline a labeled box adds up to +8.23%, but the same box drops a strong 75.3% anatomical baseline by 13.33%, because it reinforces the conflicting view. And the prior is real: with no image at all, anatomical relationships hold at 69.3% (against 74.0% with the image), while colloquial ones collapse to 40.4%, since there is no memorized prior for view-relative phrasing.
Why it matters, and what it doesn't claim
MIS-Ground reframes a field that had mostly reported failure. VLMs are not randomly guessing at anatomy in 3D; they are brittle in a specific, locatable place, and MIS-SemSam shows a chunk of that brittleness is recoverable at decode time for free. Because the fix needs only next-token logits and input embeddings, it applies to any VLM that exposes them.
Two honest caveats. Our strongest empirical evidence is on the Qwen3-VL family; MIS-Ground itself spans many model families, but "model-agnostic" here is an algorithmic property, not a claim of broad empirical validation. And spatial grounding is only part of what clinical practice needs. Report generation, and the gap between benchmark skill and bedside use, stay open. We release the benchmark and code so the community can push on both.
Abstract
Vision language models (VLMs) have shown significant promise in visual grounding for images as well as videos. In medical imaging research, VLMs represent a bridge between object detection and segmentation, and report understanding and generation. However, spatial grounding of anatomical structures in the three-dimensional space of medical images poses many unique challenges. In this study, we examine image modalities, slice directions, and coordinate systems as differentiating factors for vision components of VLMs, and the use of anatomical, directional, and relational terminology as factors for the language components. We then demonstrate that visual and textual prompting systems such as labels, bounding boxes, and mask overlays have varying effects on the spatial grounding ability of VLMs. To enable measurement and reproducibility, we introduce MIS-Ground, a benchmark that comprehensively tests a VLM for vulnerabilities against specific modes of Medical Image Spatial Grounding. We release MIS-Ground to the public at github.com/asy51/mis-ground. In addition, we present MIS-SemSam, a low-cost, inference-time, and model-agnostic optimization of VLMs that improves their spatial grounding ability with the use of Semantic Sampling. We find that MIS-SemSam improves the accuracy of Qwen3-VL-32B on MIS-Ground by 13.06%.
We release MIS-Ground publicly at github.com/asy51/mis-ground. If you work on medical VLMs or decode-time methods and want to compare notes, my email is in the footer.