Don’t Pass@𝑘: A Bayesian Framework for Large Language Model Evaluation
- 1Department of Computer and Data Sciences, Case Western Reserve University, Cleveland, OH, USA
- 2Department of Physics, Case Western Reserve University, Cleveland, OH, USA
Update👋 I’m working on a follow-up to this project. If you’d like to discuss it, my email is in the footer.
TL;DR: Replace Pass@ with a posterior-based protocol, Bayes@, that gives more stable rankings, credible intervals, and a clear decision rule while handling both binary and graded evaluation. Avg@ can be reported alongside it, since the two are rank-equivalent under a uniform prior.
Story Behind the Paper
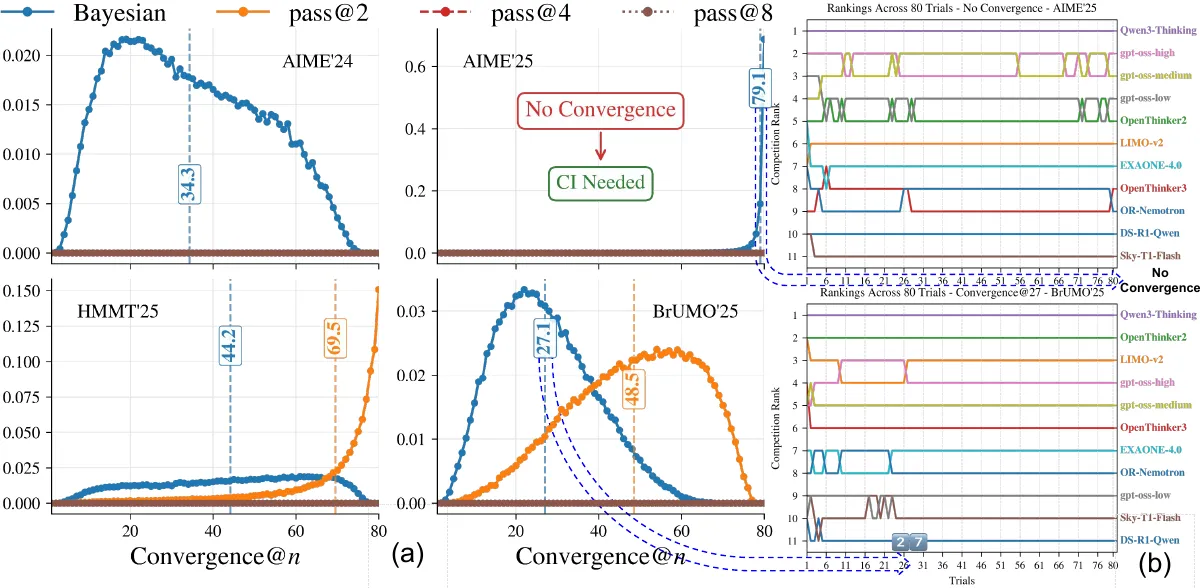
We were benchmarking reasoning models such as DeepSeek-R1 and Qwen-thinking, and kept coming back to a deceptively simple question: how many trials are enough? We took models from several families, including DeepSeek-distilled, Qwen, Microsoft, and Nvidia, ran trials, and recorded the ranking. Out of curiosity, we ran one more trial, and the leaderboard changed. At trials it changed again. We pushed to , and even then AIME’25 did not settle into a stable order. That instability led us to study the problem systematically, including with simulations. With non-deterministic decoding such as top_p, how many trials do we actually need? And if we knew the right , which evaluation metric would best estimate a model’s true performance? This paper answers those questions.
Using It in Practice
scorio is available for Python with pip install scorio and for Julia with pkg> add Scorio. Besides Bayes@, it supports avg@, Pass@, Pass^, G-Pass@, and mG-Pass@. The source code is at https://mohsenhariri.github.io/scorio, with documentation at https://scorio.readthedocs.io. For worked examples, see the Bayes evaluation tutorial.
Consider a dataset with questions. For each question, the LLM generates independent trials (samples), and each trial is evaluated with a rubric that assigns one of categories: . The results are stored in an matrix , where denotes the category of the -th trial for question . We can also include prior runs in a matrix with trials per question.
The simplest and most common rubric is binary (), where each trial is either correct () or incorrect (). In that setting, the results matrix contains only s and s, as in the example below:
Python
import numpy as np
from scorio import eval
R_binary = np.array([
[1, 1, 1, 1, 1],
[1, 1, 1, 0, 1],
[1, 0, 0, 1, 0],
[0, 0, 1, 0, 0],
], dtype=int)
w = [0, 1] # 0 for incorrect, 1 for correct
mu, sigma = eval.bayes(R_binary, w)Julia
using Scorio
w = [0, 1]
mu, sigma = bayes(R, w)| Function | Returns | Description |
|---|---|---|
bayes(R, w, R0) | Bayesian posterior mean and uncertainty | |
bayes_ci(R, w, R0) | Bayesian posterior mean and uncertainty + credible interval | |
avg(R, w) | Weighted average and uncertainty | |
avg_ci(R, w) | Weighted average and uncertainty + credible interval | |
pass_at_k(R, k) | Pass@ estimate | |
pass_at_k_ci(R, k) | Pass@ estimate + credible interval | |
pass_hat_k(R, k) | Pass^ | |
pass_hat_k_ci(R, k) | Pass^ + credible interval | |
g_pass_at_k_tau(R, k, tau) | G-Pass@ | |
mg_pass_at_k(R, k) | mG-Pass@ |
Abstract
Pass@ is widely used to report LLM reasoning performance, but with limited samples it can produce unstable and misleading rankings. We present a Bayesian evaluation framework that replaces Pass@ and average accuracy over trials with posterior estimates of a model’s underlying success probability and credible intervals. This gives more stable rankings and a transparent rule for deciding when two models differ. Evaluation outcomes are modeled as categorical rather than just with a Dirichlet prior, giving closed-form expressions for the posterior mean and uncertainty of any weighted rubric and allowing prior evidence when appropriate. Under a uniform prior, the Bayesian posterior mean is order-equivalent to average accuracy, or Pass@, which helps explain its empirical stability while adding uncertainty estimates. In simulations with known ground-truth success rates, and on AIME’24/’25, HMMT’25, and BrUMO’25, the Bayesian/avg procedure converges faster and gives more stable rankings than Pass@ and recent variants, making reliable comparisons possible with far fewer samples. The framework separates statistically meaningful gaps, where credible intervals do not overlap, from noise, and extends naturally to graded, rubric-based evaluations. These results support replacing Pass@ for LLM evaluation and ranking with a posterior-based, compute-efficient protocol that handles binary and non-binary evaluation while making uncertainty explicit. Source code is available at https://mohsenhariri.github.io/scorio.
Evaluating the Evaluation Metrics
We start by fixing a gold standard ranking using a large trial budget. For each metric, such as avg@, Pass@, and its variants, we compute the ranking at smaller , where (or for the Pass@ family), and compare it with the gold standard using Kendall’s across bootstrap replicates. In our experiments on AIME’24 and AIME’25, HMMT’25, and BrUMO’25, Bayes@ and avg@ climb to higher faster and reach a better plateau than Pass@ methods, indicating quicker and more stable agreement with the reference ranking.
To make uncertainty explicit, we use credible intervals and a clear decision rule. We approximate the posterior for as normal and compare two models with the score
and map to a ranking confidence
We only call a winner when credible intervals do not overlap or when exceeds a preset threshold, such as for approximately .
Finally, we report convergence@, the smallest after which a method’s ranking matches the gold standard and stays fixed, and estimate its distribution via bootstrap. In practice, we summarize this with convergence() PMFs and CDFs. On the math reasoning benchmarks above, Bayes@ converges reliably with fewer trials than Pass@ variants, which sometimes never settle. A lower mean convergence@ indicates a more compute-efficient evaluation metric.
Why Pass@ Is Problematic
Pass@ produces high variance and unstable rankings at small evaluation budgets, which makes model comparisons noisy. It also gives no direct uncertainty estimate; bootstrapping can be unreliable when is small. In practice, Pass@ converges more slowly to the true model ranking and often fails to stabilize within a reasonable trial budget, unlike Bayes@ or avg@. Because Pass@ reduces outcomes to a simple “any success” criterion, it is also poorly suited to graded or rubric-based evaluations, where partial or categorical correctness matters.
Simulation
Try out the interactive demo below.
Algorithm
In principle, we could estimate by running an arbitrarily large number of trials with the LLM, yielding an accurate estimate of . In practice, compute limits usually force us to work with small . Our goal is to use a Bayesian approach to estimate and its uncertainty from a finite .
The first step is to construct the posterior distribution
the probability of given the -th row of the matrix , denoted . This posterior depends on the observed data and a chosen prior distribution for the unknown underlying probability vector . The prior can be uniform, when no prior information is available, or it can encode previously gathered evidence about the LLM’s performance.
The Bayesian estimate uses two key quantities:
Posterior mean of , denoted , which is the mean of over the joint posterior for all questions:
This is the Bayesian optimal estimator, minimizing the quadratic loss function
over all possible estimators , where the expectation is taken over all possible and realizations of .
Posterior variance, denoted , which quantifies uncertainty in the estimate :
Both and have exact closed-form expressions, derived in Appendix A of the paper, and can be computed efficiently for any using the algorithm below.
Code Examples
Categorical Evaluation with Correctness and token_ratio
Bayes@ can score more than binary correctness. Here, correctness stores the binary outcome and token_ratio marks answers that are too long. The snippet turns those two signals into four categories, then uses w to give full credit to correct, efficient answers, partial credit to correct, verbose answers, and a small score to efficient wrong answers. In other words, concise correct responses receive full credit, verbose correct responses receive partial credit, and efficient wrong responses receive a small score.
import numpy as np
from scorio import eval
correctness = np.array([
[1, 1, 0, 1],
[1, 0, 0, 1],
[0, 1, 1, 1],
[1, 1, 0, 0],
], dtype=int)
token_ratio = np.array([
[0.80, 1.60, 0.90, 1.10],
[1.40, 1.00, 1.70, 0.70],
[1.80, 0.90, 1.40, 0.95],
[0.85, 1.30, 1.10, 1.60],
])
length_threshold = 1.20
verbose = token_ratio > length_threshold
# 0 = wrong & verbose, 1 = wrong & efficient,
# 2 = correct & verbose, 3 = correct & efficient
R_cat = np.where(
correctness == 1,
np.where(verbose, 2, 3),
np.where(verbose, 0, 1),
).astype(int)
w = np.array([0.0, 0.2, 0.75, 1.0])
mu_binary, sigma_binary = eval.bayes(correctness)
mu_cat, sigma_cat = eval.bayes(R_cat, w)
# binary evaluation
print(f"mu={mu_binary:.4f}, sigma={sigma_binary:.4f}")
# categorical evaluation
print(f"mu={mu_cat:.4f}, sigma={sigma_cat:.4f}")Greedy Run as Prior Evidence for top_p Samples
top_p_runs contains seven stochastic samples for each question. greedy_prior adds one deterministic greedy run per question as R0, so the posterior starts from that earlier evidence rather than from a uniform prior alone. The two bayes_ci calls report the estimate with and without the prior; in this toy data, the greedy run nudges the mean upward and narrows the interval.
import numpy as np
from scorio import eval
# M = 5 questions, N = 7 sampled runs per question
top_p_runs = np.array([
[1, 1, 1, 1, 0, 1, 1],
[1, 0, 0, 1, 0, 0, 1],
[0, 0, 0, 0, 1, 0, 0],
[1, 1, 1, 0, 1, 1, 0],
[0, 0, 1, 0, 0, 0, 0],
], dtype=int)
greedy_prior = np.array([
[1],
[1],
[0],
[1],
[0],
], dtype=int)
mu, sigma, lo, hi = eval.bayes_ci(top_p_runs)
mu_prior, sigma_prior, lo_p, hi_p = eval.bayes_ci(top_p_runs, R0=greedy_prior)
# without prior: mu=0.4667, sigma=0.0629, 95% CrI=[0.3435, 0.5899]
print(f"mu={mu:.4f}, sigma={sigma:.4f}, " f"95% CrI=[{lo:.4f}, {hi:.4f}]")
# with greedy prior: mu=0.4800, sigma=0.0585, 95% CrI=[0.3654, 0.5946]
print(f"mu={mu_prior:.4f}, sigma={sigma_prior:.4f}, " f"95% CrI=[{lo_p:.4f}, {hi_p:.4f}]")For more detail, choose the in-depth version from the left sidebar.
Comments